
당니의 개발자 스토리
영속성 컨텍스트 2 본문
영속성 컨텍스트 2
여기부터 다시 해볼게요.

영속성 컨텍스트는 내부에 1차 캐시라는 걸 들고 있습니다. 제가 예를 들어서 Member 객체를 생성을 합니다. 그리고 값을 세팅을 했죠. 지금 setUsername 까지는 비영속 상태입니다.
자 그리고 지금 만든 Member 객체를 em.persist 해서 딱 집어 넣으면 무슨 일이 발생하냐면, 여기 영속성 컨텍스트 보이시죠.
지금은 엔티티 매니저 자체가 영속성 컨텍스트로 이해를 하셔도 됩니다. 물론 약간 미묘한 차이는 있어요.
일단 여기 내부에는 1차 캐시라는 게 있습니다. 사실 이 1차 캐시를 영속성 컨텍스트로 이해하셔도 되는데요.
여기 보시면 @Id가 있고 Entity가 있죠. 그러니까 지금 맵이 있는데, 저희가 DB pk 로 맵핑한 걔가 key가 되구요. 값이 뭐냐면 이 엔티티 객체 자체가 value가 됩니다.
그래서 지금 같은 경우에는 key가 member1, 그리고 방금 여러분이 저장하신 이 Member 객체 자체가 값이 됩니다.
자 그럼 이렇게 되면 무슨 이점이 있지?
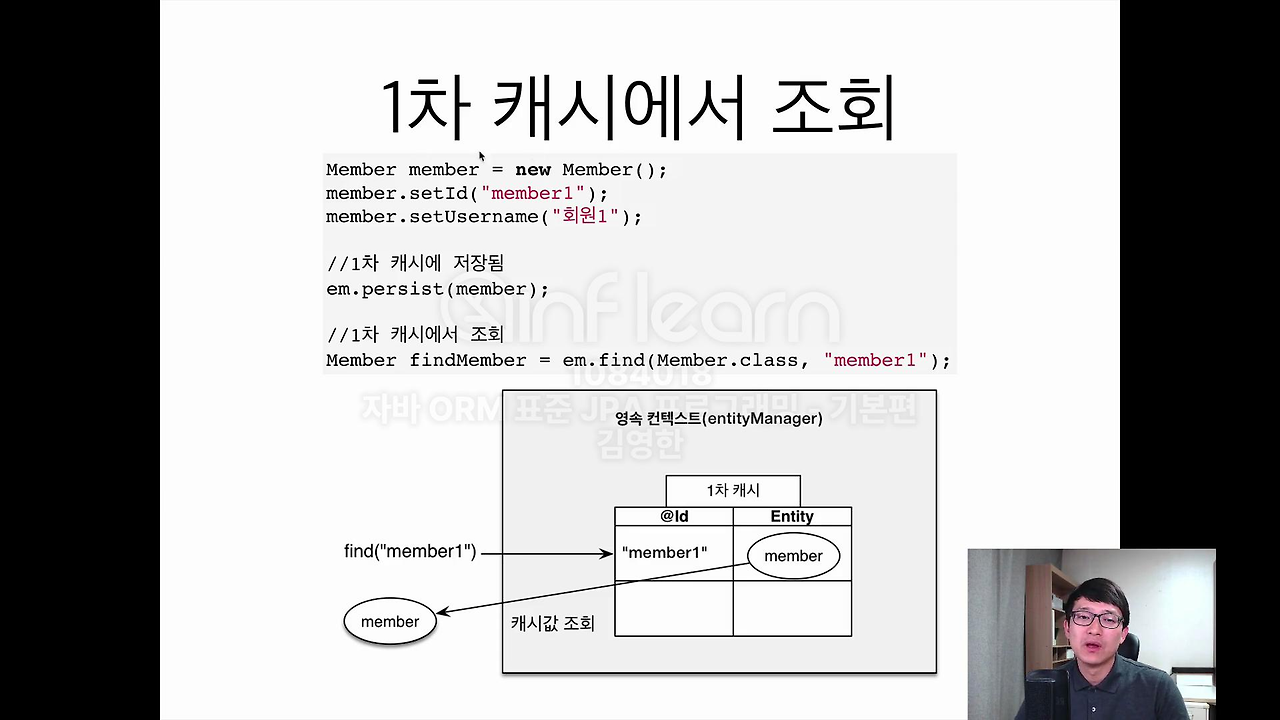
이제 조회할 때 제가 이렇게 Member 객체를 저장을 해놓고 만약에 조회를 해요. 그러면 jpa는, em.find로 member1을 조회를 하면 jpa는 우선 어떤 시도를 하냐면 이 영속성 컨텍스트에 있는 1차 캐시를 뒤집니다. DB를 뒤지는게 아니라.
그래서 1차 캐시에 보니까 Member 엔티티가 있네? 그럼 캐시에 있는 값을 그냥 조회해옵니다. 그래서 이런 1차 캐시에서 조회한다는 이점이 있습니다.

자 그런데 지금 member2번을 만약에 조회를 해요. 그럼 member2번은 방금 시나리오에서는 1차 캐시에 없었죠. 그러니까 DB에는 있고 1차 캐시는 없다고 칩시다.
그럼 일단 find 해서 member2를 찾습니다. 보니까 1차 캐시에 없죠. 그러면 jpa가 '영속성 컨텍스트 안에 있는 1차 캐시에 member2가 없네?' 하면서 db에 가서 조회를 합니다. 물론 뭐 db에 member2가 있어야 되겠죠. 그래서 db에서 조회한 그 member2를 여기에 있는 1차 캐시라는 데다가 저장을 합니다. 그리고 member2를 반환 합니다. 이후에 member2를 다시 조회하게 되면, 영속성 컨텍스트 안에 1차 캐시에 있는 member2가 반환이 되겠죠. DB를 조회하지 않고서 이러한 이점을 얻을 수 있는데 사실 이게 뭐 그렇게 큰 도움은 안돼요.
왜냐면 뭐 뒤에서 배우겠지만 엔티티 매니저라는 것은 데이터베이스 트랜잭션 단위로 보통 만들고, 데이터베이스 트랜잭션이 끝날 때 영속성 컨텍스트를 같이 종료시켜 버려요.
무슨 말이냐면 고객의 요청이 하나 들어와서 보통 비즈니스가 끝나버리면 이 영속성 컨텍스트를 지운다는 거거든요. 그럼 1차 캐시도 다 날라가요. 그렇기 때문에 굉장히 짧은 찰나의 순간에서만 얘가 이득이 있기 때문에 그 막 여러 명의 고객이 사용하는 그런 캐시가 아닌 거예요.
애플리케이션 전체에서 공유하는 캐시는 이제 JPA나 Hibernate 에서는 2차 캐시라고 그러고요. 1차 캐시는 정말 데이터베이스 한 트랜잭션 안에서만 효과가 있기 때문에 사실 막 그렇게 성능의 이점을 크게 얻을 수 있는 장점은 없습니다.
이거를 코드로 한번 보여 드리겠습니다.

지금 딱 여기까지 코드가 되었죠?
자 em.persist로 저장된 거를 제가 조회해 볼게요. 지금 DB에 100L 값이 있어서 101로 값을 좀 바꾼 다음에 저장을 하고 조회해 볼게요.

이렇게 조회한 다음에
출력을 해보겠습니다. 이제 여기서 중요한 건 조회용 sql이 나가는지가 중요한 거겠죠.
그래서 돌려보면,

before랑 after가 지나고 지금 잘 보시면 findMember에서 값을 찍는데 select query가 안나갔죠. 뒤에 insert 쿼리는 뒤에서 설명드릴거고, 지금 우리가 조회를 했는데 데이터베이스에 select 쿼리가 안 나갔잖아요. 왜냐?
여기서 저장을 할 때 어디에 저장이 된다 했죠? 1차 캐시에 저장이 된 거예요. 그리고 나는 똑같은 PK로 값을 가져왔기 때문에 DB에서 가져오는 게 아니라 먼저 1차 캐시에 있는 거를 조회한 거죠.

자 그럼 이번에는 코드를 좀 지우고, 이제 101번을 저장했으니까 지금 db에 남아있죠.
그래서 이번에는 101번을 찾아요. 지금 새로 실행하니까
새로 실행하게 되면 이게 다시 다 생성이 되면서 영속성 컨텍스트라는 것도 완전 새로 생성이 되겠죠. 이 엔티티 매니저 생성이 될 때.

자 그러면 이렇게 하고 101L을 두 번 조회해 보겠습니다.

그러면 1번을 조회할 때는 지금 똑같은 식별자예요. 첫 번째 조회할 때는 db에서 쿼리를 날려서 가져와야 돼요.
근데 두 번째 조회할 때는 쿼리가 나가면 안돼요. 1차 캐시라는 곳에서 조회가 되야되죠.

여기 방금 공유해드렸던 이 시나리오대로 똑같은 걸 두 번 조회할 때는 두 번째부터는 1차 캐시해서 가져온다.
한번 다시 돌려보면,

자 여기 보시면 Query가 한 번만 나갔습니다.

왜냐면 제가 101번을 가지고 올 때 JPA가 DB에서 가지고 와서 영속성 컨텍스트에 일단 올려놔요. 무조건 JPA는 엔티티를 딱 조회하거나 하면 무조건 영속성 컨텍스트 다 올립니다.
그리고 두 번째에 똑같은 걸로 조회하니까 조회하는 시점에 영속성 컨텍스트 안에 있는 1차 캐시부터 뒤집니다. 뒤지면 방금 조회를 했기 때문에 여기 안에 있는 거예요. 그럼 있는 애를 반환하게 되는 겁니다.
그래서 이게 뭐 일반적으로는 큰 도움은 안되는데 막 비즈니스가 정말 복잡할 때가 있어요. 이제 그럴 때는 막 같은 거를 조회할 때도 있거든요. 그럼 그럴 때 쿼리가 좀 줄어들겠죠. 사실 현업에서 막 크게 도움을 주진 않아요. 오히려 이런 것보다는 나중에 컨셉을 이해하시면 오히려 성능적인 이점보다는 이 컨셉이 주는 이점이 있어요. 좀 더 객체 지향적으로 코드를 작성하거나 하는 데 있어서 이점이 있습니다. 그거는 이제 뒤에서 설명드릴게요.
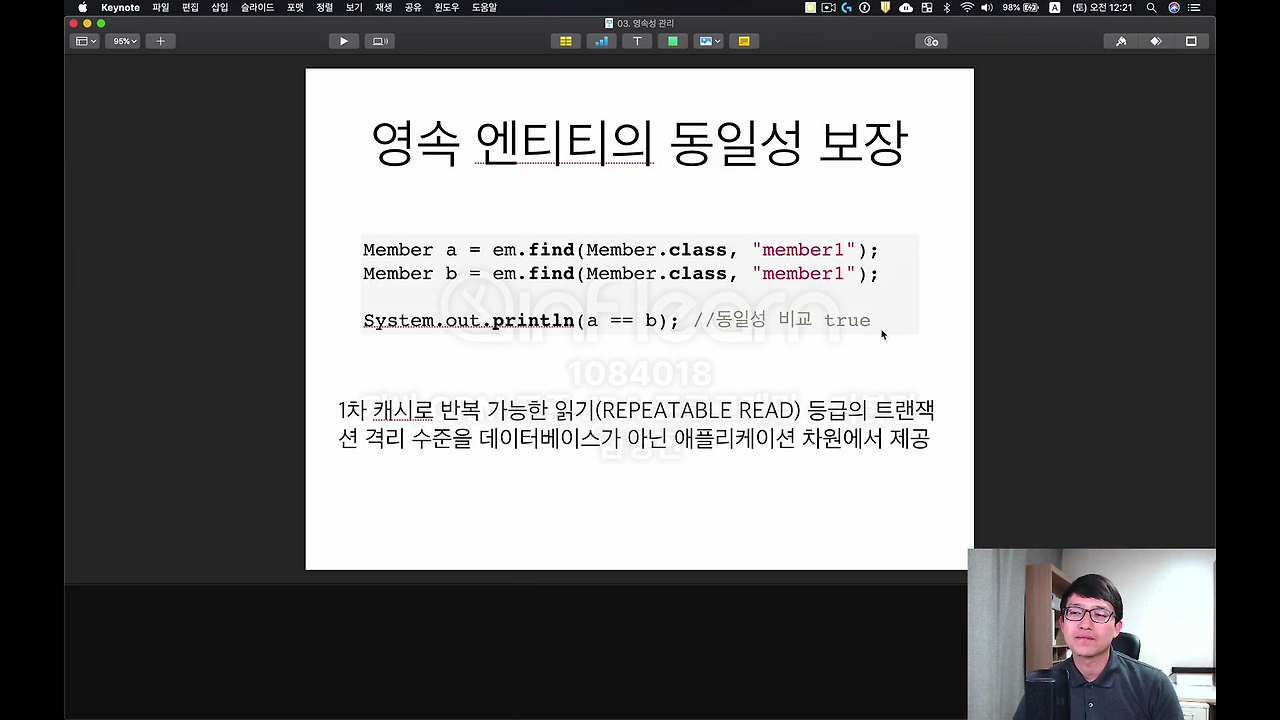
자 그 다음에 영속 엔티티의 동일성 보장, 이건 무슨 얘기냐면
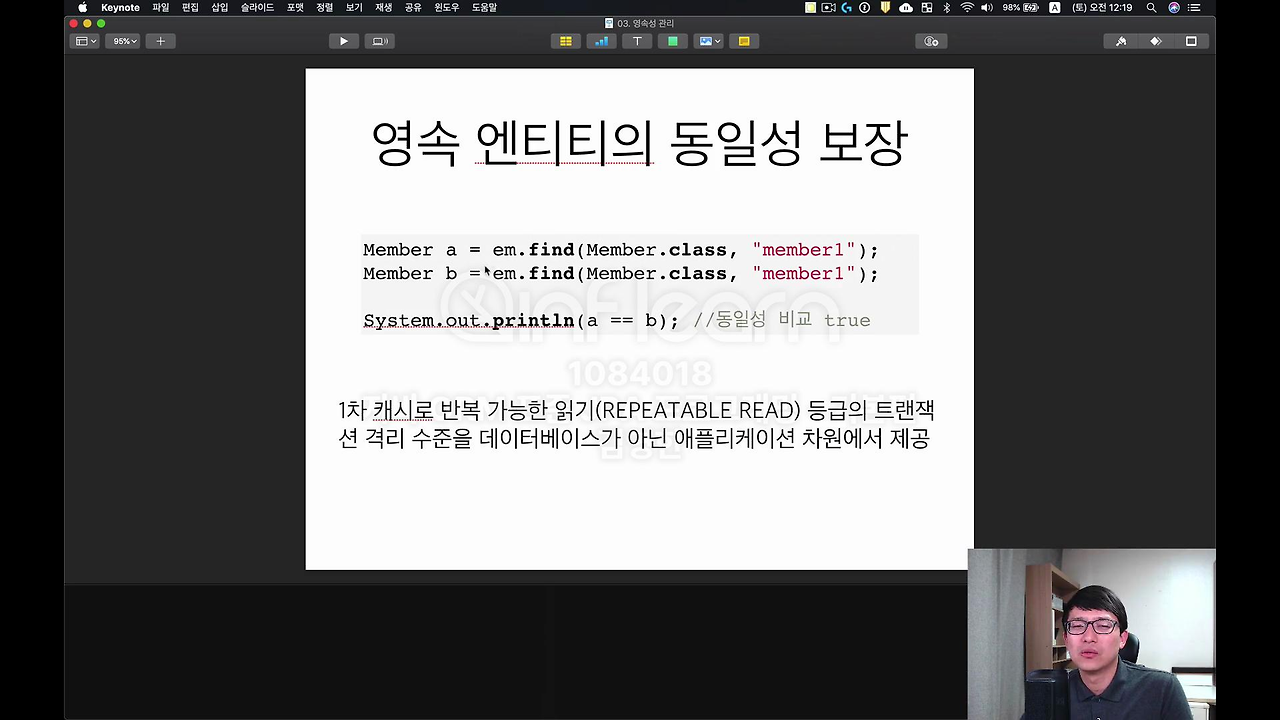
우리가 이제 Java Collection 에서 똑같은 거를 가지고 와서 == 비교하면 똑같죠. JPA도 뭐가 있냐면 영속 엔티티의 동일성 이라는 걸 보장을 해줍니다.
자 코드를 보시면 제가 똑같은 101L을 조회했죠. 그럼 이거를 == 비교하면 어떻게 되느냐?
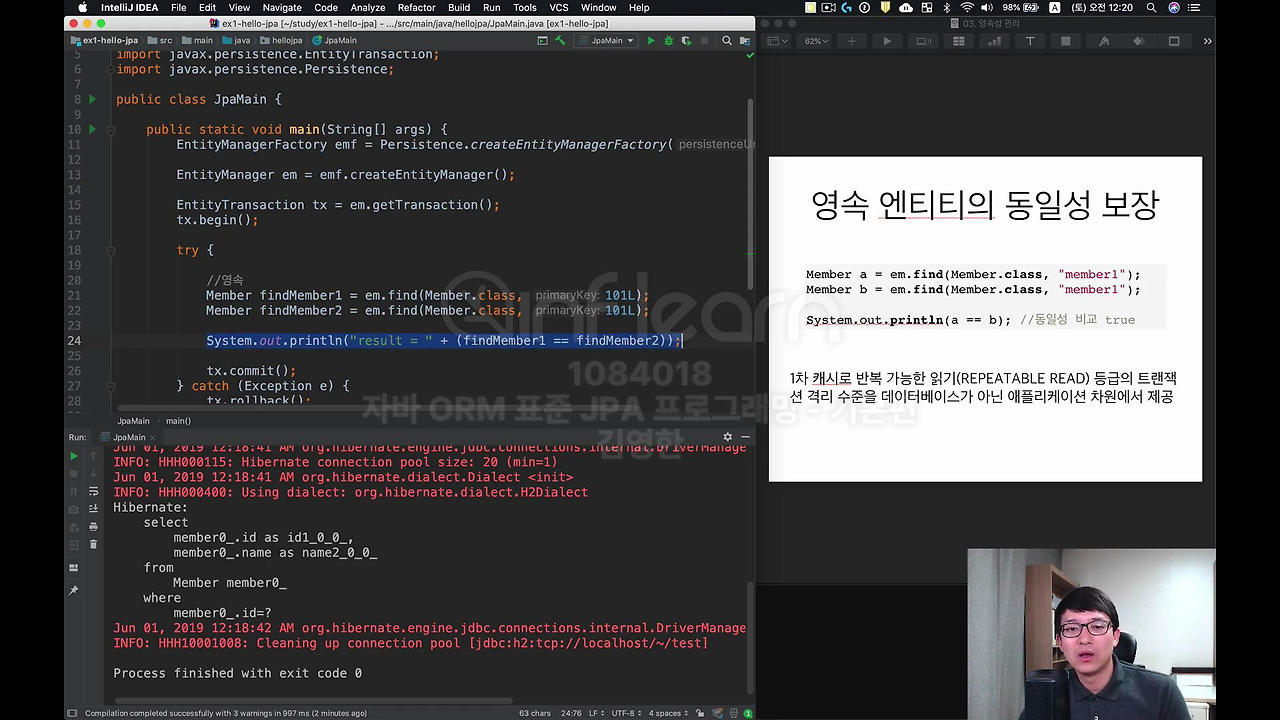
이렇게 하고 실행해 보겠습니다. 보시면,

여기 true가 나오죠. 무슨 말이냐면 이제 jpa 는 마치 내가 Java 컬렉션에서 가져왔을 때는 주소가 같잖아요. 그런 것처럼 jpa 가 이 영속 엔티티의 동일성을 보장해줍니다. 즉 == 비교를 보장해는 거죠.
마치 우리가 Java 컬렉션에서 꺼내서 똑같은 레퍼런스가 있는 객체를 꺼내면 == 비교 했을 때 똑같은 것처럼 해줍니다.
이게 가능한 이유가 방금처럼 1차 캐시가 있기 때문에 이런게 가능한 거죠. 이거를 조금 어렵게 설명을 하면,
1차 캐시로 반복 가능한 읽기 데이터베이스의 트랜잭션 격리 수준을 REPEATABLE READ 등급의 트랜잭션 격리 수준을 데이터베이스가 아닌 애플리케이션 차원에서 제공해준다. 라고 이해하시면 되는데요.
이개 조금 어려운 내용이어서 그냥 JPA에서 똑같은 거를 조회하면, 물론 같은 트랜잭션 안에서 실행을 해야 돼요. 그러면 == 비교 했을 때 true가 나온다 라고 이해하시면 됩니다.
자 그 다음에 이 영속성 컨텍스트가 있음으로 해서 어떤 게 가능하냐면,
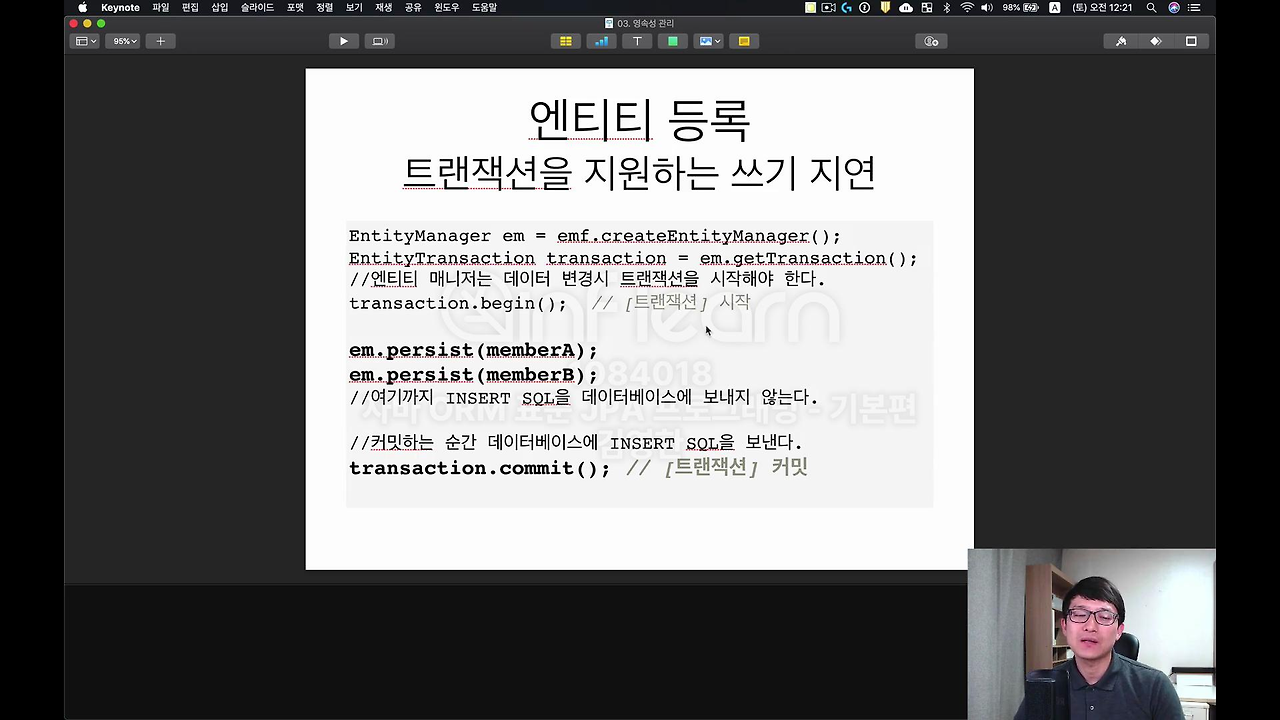
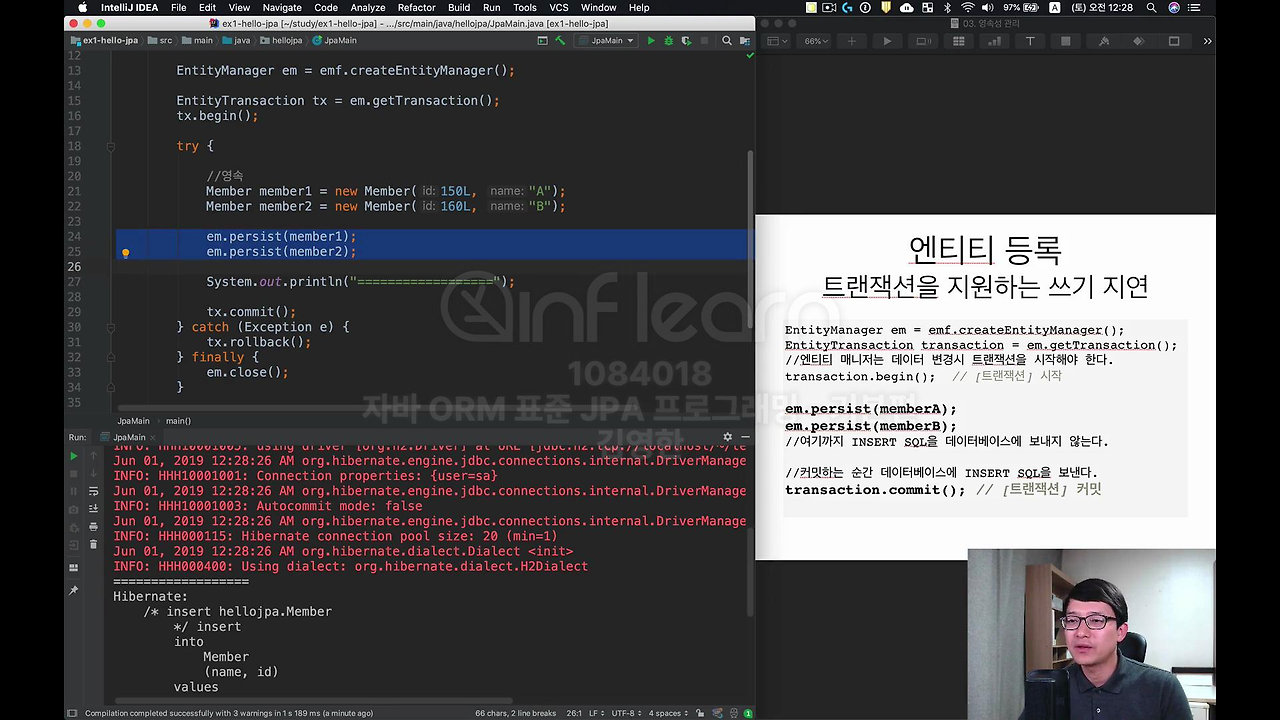
엔티티를 등록할 때 트랜잭션을 지원하는 쓰기 지연이라는 게 가능합니다. 뭐냐면 이거는 여기 코드를 그냥 대충 설명해 드릴게요.
먼저 트랜잭션 딱 실행하고 어떻게 합니까? em.persist로 memberA, memberB 이렇게 넣어놔요. 그런데 JPA는 재미있는 게 여기까지 insert SQL을 데이터베이스로 보내지 않아요. 물론 예외도 있는데 나중에 뒤에 설명 드릴 건데 기본적으로는 insert SQL을 DB에 보내지 않아요. 그냥 JPA가 이걸 쭉쭉 쌓고 있어요. 그리고 제가 이 트랜잭션을 커밋 하는 순간에 insert SQL을 데이터베이스에 보냅니다.
그래서 실제 내부적으로 어떻게 되냐면,

제가 em.persist로 해서 memberA를 넣습니다. 그리고 em.persist로 memberB를 넣습니다. 순차적으로 넣었을 때 jpa 안에서 무슨 일이 벌어지는지 한번 설명을 드리겠습니다.
일단 memberA를 딱 저장을 하면 이런 일이 벌어집니다. 영속성 컨텍스트 안에는 1차 캐시도 있는데 또 뭐가 있냐면 쓰기 지연 SQL 저장소라는 재미난 게 있습니다. 그래서 memberA를 em.persist해서 넣잖아요. 그러면 memberA가 일단 1차 캐시에 들어갑니다. 그러면서 동시에 무슨 일이 발생되냐면 JPA가 이 엔티티를 분석을 해서 insert 쿼리를 생성을 합니다. 그리고 쓰기 지연 SQL 저장소를 그곳에 쌓아둡니다.
그 다음에 memberB도 em.persist 하잖아요. 얘도 마찬가지로 insert SQL을 생성을 해서 이거를 쓰기 지연 SQL 저장소에 차곡차곡 쌓아둡니다.
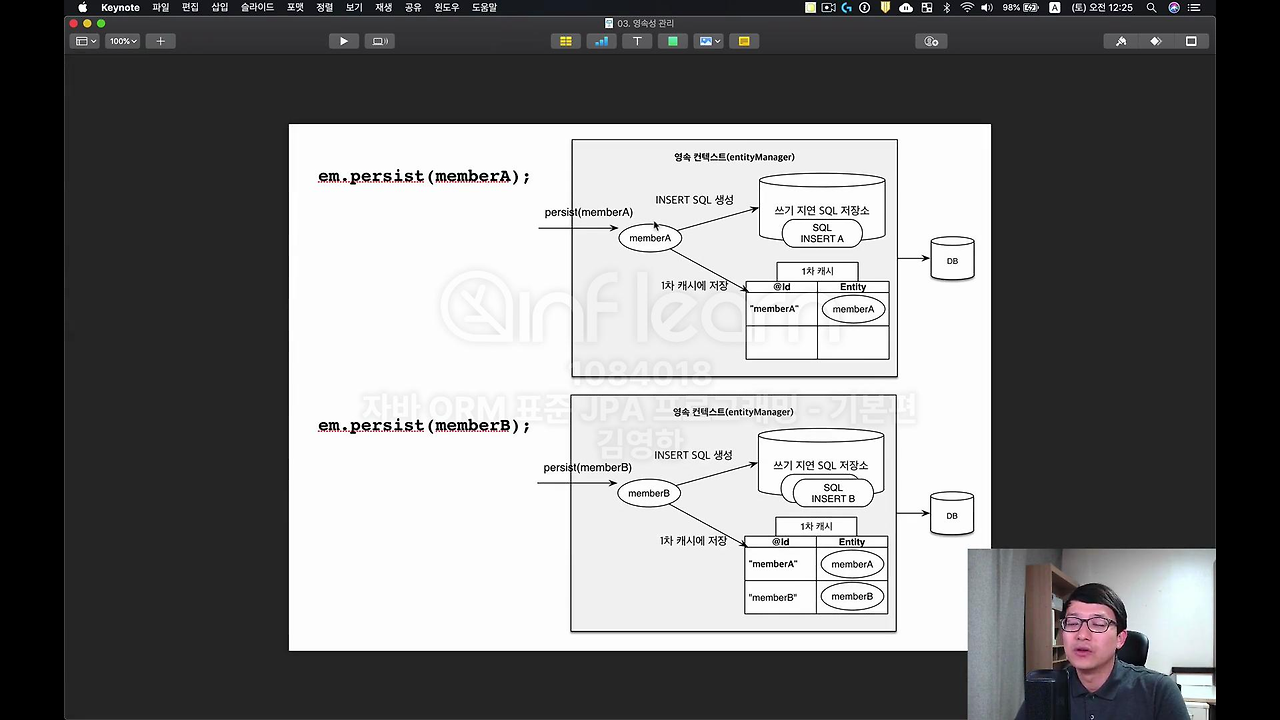
지금 A랑 B 둘 다 쌓여있죠. 그럼 언제 데이터베이스에 이 쿼리가 날라가냐면 트랜잭션을 커밋하는 시점에 제가 딱 커밋을 때리면 이 쓰기 지연 SQL 저장소에 있던 애들이, jpa에서는 flush라고 하는데 flush가 딱 되면서 날라갑니다.
그리고 실제 데이터베이스 트랜잭션이 딱 커밋됩니다.

이 메커니즘으로 돌게 되구요. 이거를 한번 보여드리겠습니다.

Member member = new Member() 하는데 귀찮으니까 생성자를 만들게요.

지금 보면 생성자를 만들었는데 오류 같은 게 나요. 이 오류는 IDLE 인텔리 제이에서 알려주는 건데 왜냐면 JPA는 기본적으로 막 내부적으로 리플렉션이나 이런 것들을 쓰기 때문에 동적으로 객체를 생성을 해야 돼요. 그래서 기본 생성자가 하나 있어야 됩니다.
꼭 public으로 해둘 필요는 없습니다.
이렇게 persist 하면,

이 persist 하는 순간에 데이터베이스에 저장되는 게 아니라 그냥 영속성 컨텍스트에 차곡차곡 엔티티도 쌓이고 쿼리도 쌓이게 됩니다. 그러다가 딱 커밋을 하는 시점에 진짜 데이터베이스의 쿼리가 딱 날아가게 됩니다.
여기 대해서 한번 출력을 다시 해볼게요.
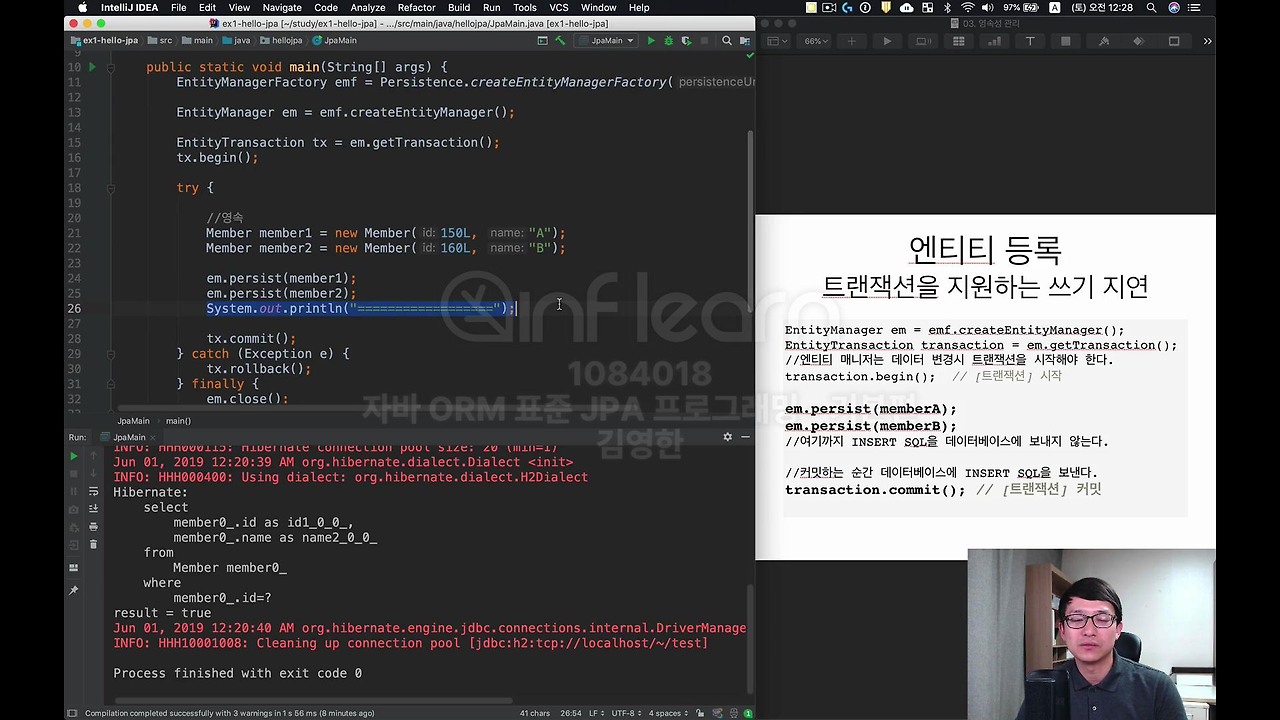
자 선을 그어서, 선이 그어진 걸 기준으로 이전의 쿼리가 나가는지 이후의 쿼리가 나가는지 보면 되겠죠?
실행해 보겠습니다.

자 보시면 insert 쿼리가 두 방이 나갔는데요. 여기 보면 선을 딱 긋고 나서 쿼리가 나가죠. 아까 말씀드린 그림이랑 똑같이 되는 겁니다.

'어? 굳이 왜 이렇게 하지? 그냥 이때 쿼리가 나가면 되지 않나?'
자 여러분 여기서 이제 버퍼링 이라는 기능을 쓸 수가 있습니다.
버퍼링이 뭐냐면
지금 만약에 내가 이 persist 할때마다 쿼리를 DB에 날려요. 그러면 뭔가 최적화 할 수 있는 여지 자체가 없어요.
사실 데이터베이스에 아무리 뭐 데이터를 집어 넣어도 결국 커밋 안하면 다 말짱 꽝 이거든요. 커밋하기 직전에만 insert를 치고 딱 커밋을 하면 돼요.
persist를 보면 member1, member2가 쌓였잖아요. 그러면 데이터베이스에 이거를 한 번에 보낼 수가 있습니다. 이걸 이제 jdbc 배치 뭐 이렇게 얘기를 하는데,

Hibernate 같은 경우에는 이 옵션이 있습니다.
이 Hibernate.jdbc.batch_size 라는 게 있는데 이거를 두시면 이 size 만큼 모아서 데이터베이스에 한 방에 네트워크로 쿼리를 딱 보내고 db를 Commit 칩니다. 버퍼링 같은 기능이 있는 거죠. 모았다가 db 에 한 번에 쫙 넣을 수 있는 거죠. 실제로는 여러 개를 db에 저장하는 경우는 특별한 배치 쿼리 짜거나 이런 거 아닌 이상은 그렇게 많지 않아서 사실 막 실시간 쿼리에서는 크게 얻을 이점이 많진 않은데 암튼 이제 중요한 건 이런 이점을 얻을 수 있다는 거예요.
그니까 막 JPA를 써서 성능이 더 떨어지나요? 라고 얘기했을 때 이런 것들을 정말 잘 활용하면 오히려 옵션 하나로 그냥 기본적으로 성능을 먹고 들어갈 수가 있어요.

내가 막 이거를 예를 들어서 MyBatis를 쓰거나 생자로 내가 쿼리를 짜요. 그럼 내가 그걸 막 지어내서 모았다가 커밋 직전에 넣는다? 이런 건 정말 힘들거든요. 그래서 버퍼링으로 모아서 write 하는 거에 대한 이점을 얻을 수 있다 라는 게 있고요.
그리고 이제 엔티티 수정.
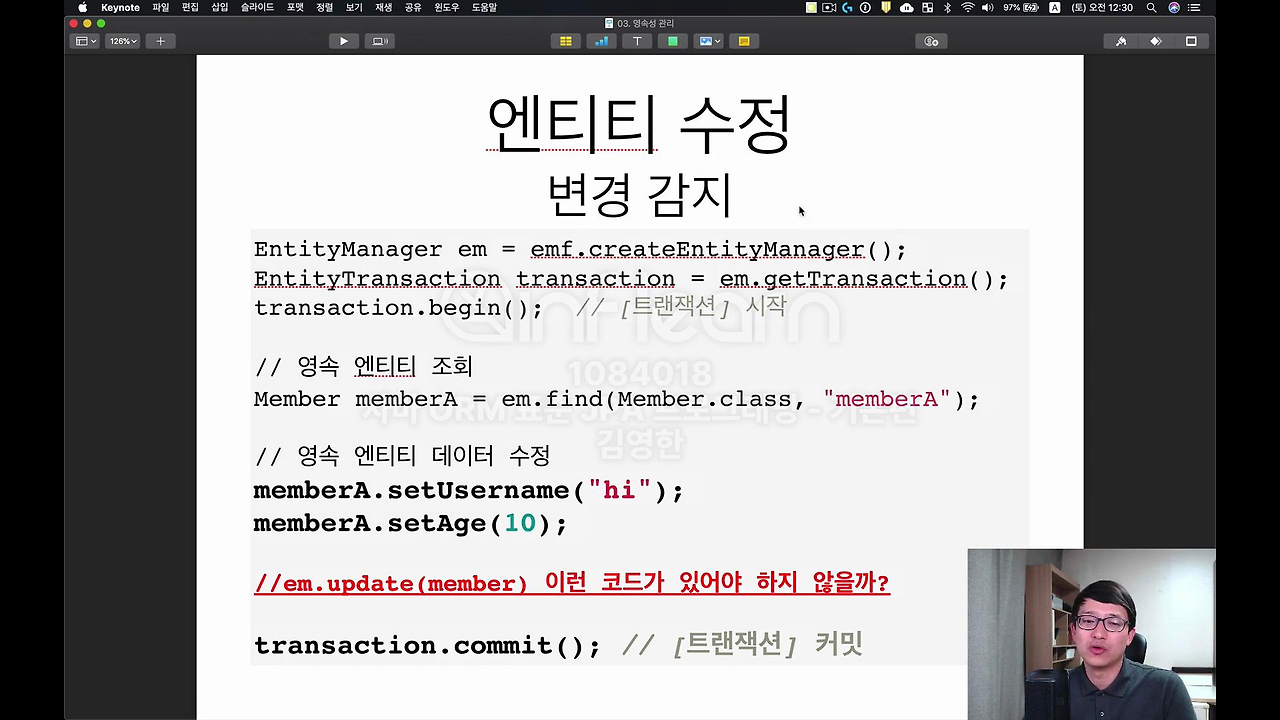
이제 변경 감지라고 Dirty Checking 이렇게 얘기하는데 이거는 제가 바로 코드로 보여드릴게요.
150을 찾고, DB에 한번 가보겠습니다.

Member를 실행해 보면 150이 A 라고 되어있거든요. 이걸 한번 변경해 보겠습니다.

이렇게 setName으로 "ZZZZ"으로 이름을 변경할게요. 여기서 JPA 처음 쓰시면, 이런 이론적인 부분을 모르면 이 부분을 되게 헷갈려 하세요.
지금 값을 변경했으니까 persist를 다시 호출해야 되는 거 아니야?
원래 보통은 데이터 변경하면 다시 데이터베이스에 반영을 해줘야 되잖아요. 근데 여러분 이거 잘 생각해 보면 제가 가장 처음 첫 시간에 설명 드렸을 것 같은데 이 JPA의 목적이 마치 Java 컬렉션 다루듯이 객체를 다루는 거거든요. 그래서 컬렉션에 넣은 것처럼 생각해보면 우리가 뭐 Java 리스트 같은 컬렉션에서 값을 꺼냈어요. 그리고 내가 값을 변경했어. 그 다음에 다시 컬렉션에 집어 넣었나요? 그렇지 않거든요.
그러니까 뭐냐면 이렇게 이 코드 자체를 쓰면 안 돼요. 오히려 이걸 써서 아무도 얻을 수 있는 게 없어요.
JPA는 딱 이렇게만 해주시면 돼요. 그래서 이렇게 find로 내가 찾아온 다음에 데이터를 변경을 해요. 딱 값만 변경했어요. 이러고 실행을 해보면,

DB에서 찾아오는 거니까 select 쿼리가 나가겠죠?

그리고 지금 update 쿼리가 실행이 됐습니다. 저는 그냥 값만 바꿨지 JPA한테 '이 값을 변경해줘' 라던가 'update 쿼리를 날려줘' 이런걸 전혀 한 게 없잖아요.
그런데 마치 내가 Java Collection 을 다루듯이 값만 바꿨는데 update 쿼리가 나간 거에요. 어떻게 된 거냐?
일단 DB를 확인해 볼게요.

자 where id는 150번 해서 실행해 보면 분명히 아까 A 였는데 지금 ZZZZ로 바뀌어 있습니다.
자 이게 어떻게 된 거지? 이제 설명을 해드리겠습니다.
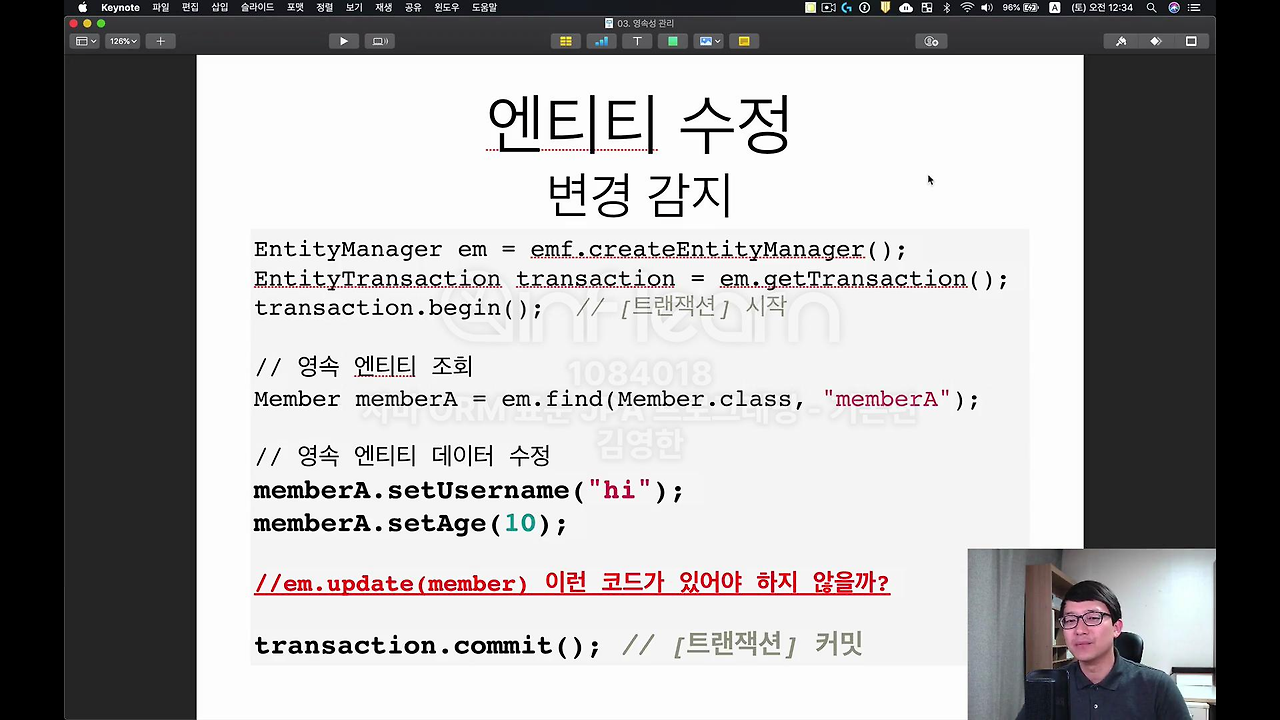
JPA는 Dirty Checking이라고 말하는데 변경 감지라는 기능으로 엔티티를 변경할 수 있게 됩니다. 마치 우리가 생각할 때는 엔티티의 값을 바꾸려면 뭔가 set해서 값을 바꾼 다음에 jpa한테 이 값을 update 쳐줘 라고 막 코드를 날려야 될 것 같은데, 그게 아니라 마치 Java 컬렉션에서 하는 것처럼 그러지 않아도 db의 값이 변경이 됩니다. 이 마법 같은 게 어떻게 된 건가?
이것에 대한 비밀은 뭐냐면,
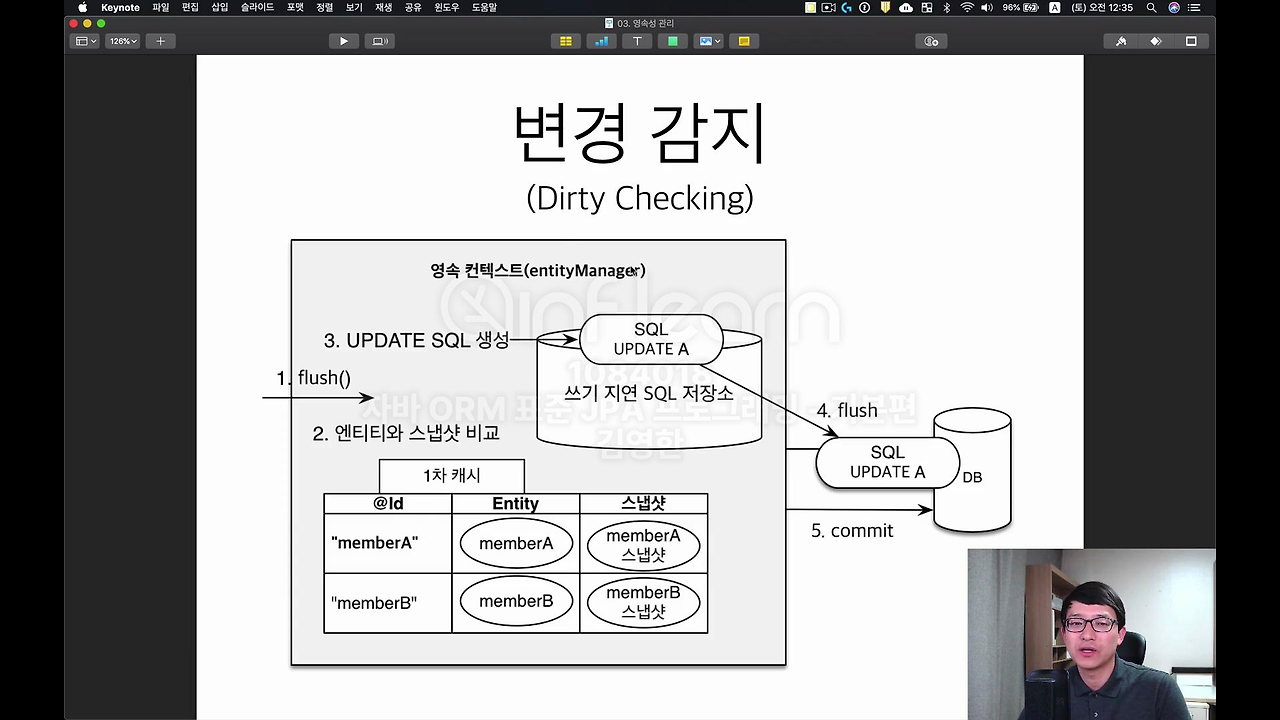
바로 이 영속성 컨텍스트 안에 다 있습니다.
자 이게 어떻게 동작하는지 설명 드릴게요.
JPA는 데이터베이스 트랜잭션을 커밋하는 시점에 무슨 일이 벌어지냐면 커밋을 하면 내부적으로 flush라는게 호출됩니다. flush는 조금 이따 설명을 드리고요. 아무튼 데이터베이스 트랜잭션을 커밋하면 이 엔티티랑 스냅샷을 비교합니다.
자 1차 캐시 안에는 사실 뭐가 있냐면 아까 PK인 ID가 있고, 이 Entity라는 게 있고 그 다음 스냅샷이라는 게 있습니다. 이제 이 스냅샷이라는 건 내가 값을 딱 읽어온 그 시점, 최초 시점의 상태를 딱 스냅샷으로 떠두는 거예요. DB에서 읽어오고 내가 여기 집어넣었던, 어쨌든 이 영속성 컨텍스트의 1차 캐시 안에 최초로 딱 들어온 상태를 딱 스냅샷을 떠둡니다. 이제 그렇게 해놓은 상태에서 지금 내가 Member의 값을 변경했잖아요. 그러면 이 JPA가 트랜잭션을 커밋 되는 시점에 내부적으로 flush라는 호출이 되면서 JPA가 엔티티랑 스냅샷을 일일이 다 비교를 합니다. 쫙 비교를 해서 물론 내부적으로는 최적 알고리즘 다 돼 있겠죠. 그렇게 비교를 딱 해보고 'memberA가 지금 바뀌었네?' 그러면 어떻게 하냐면 update 쿼리를 여기 쓰기 지연 SQL 저장소에 또 만들어둡니다. 그리고 update 쿼리를 데이터베이스에 반영하고 커밋 하게 됩니다. 이거를 이제 변경 감지라고 하고요. 이런 메커니즘으로 이 기능이 동작하게 됩니다.
그 다음에 이제 엔티티 삭제.
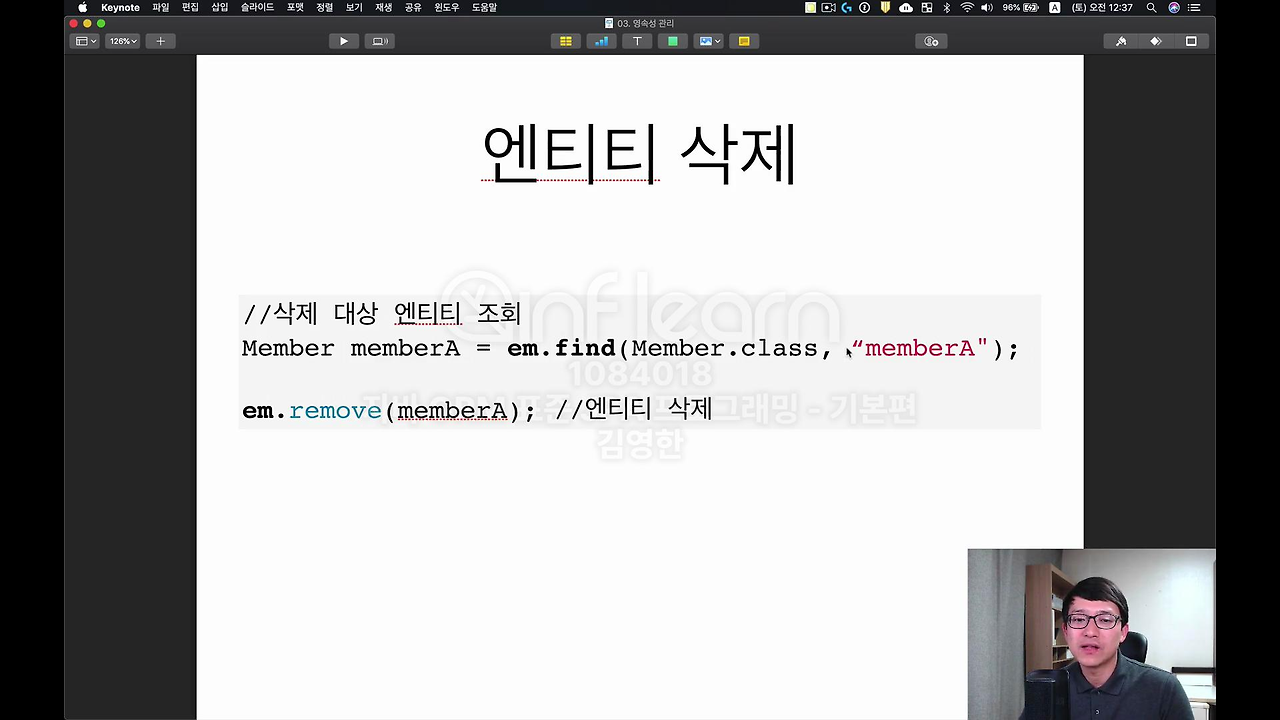
삭제는 이렇게 엔티티를 찾아와서 remove 하면 삭제가 됩니다. 이거는 방금 봤던 메커니즘이랑 똑같구요. 트랜잭션 커밋 시점에 delete 쿼리가 나간다고 보시면 돼요.
자 그러면 변경까지 설명을 드렸는데, 가끔 질문을 하세요.
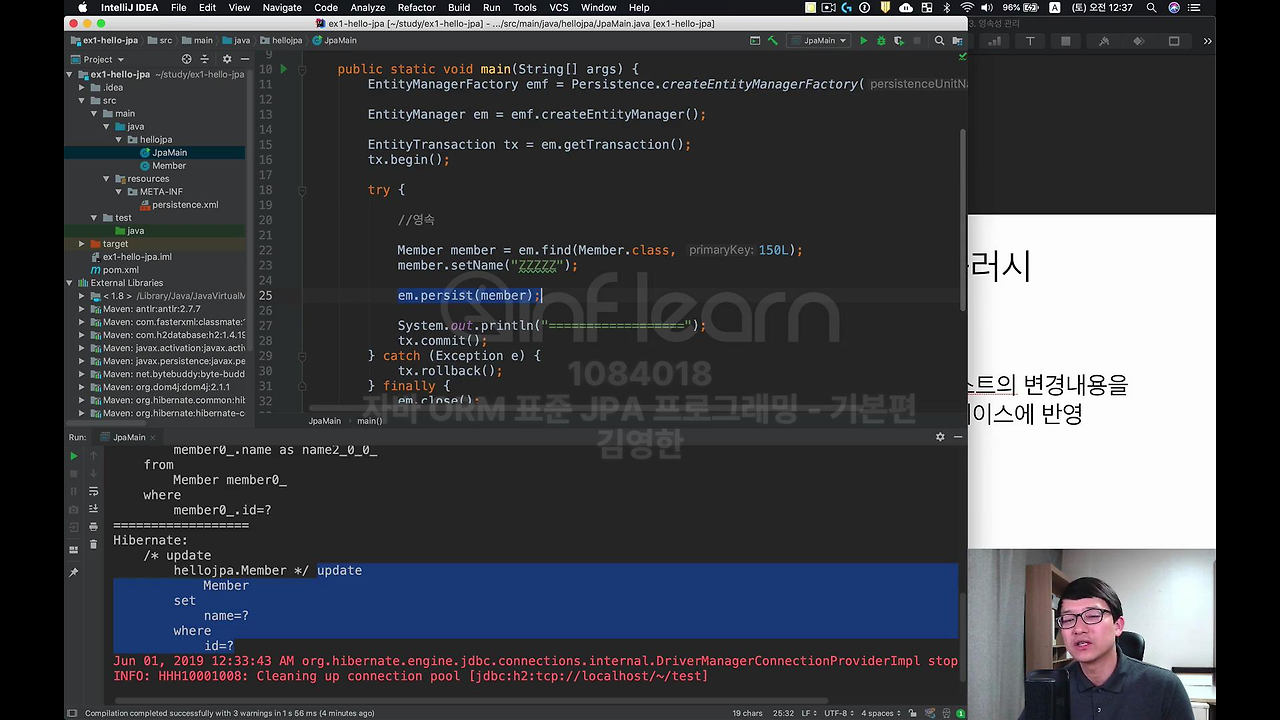
그래도 변경을 했는데 em.persist를 호출을 해야 되지 않나요? 등등 여러가지 질문들이 있는데 결론부터 말씀드리면,

이거를 호출하지 않는게 정답입니다.
엔티티를 변경하려면 어떻게 해야 돼요?

그냥 이렇게 변경하시면 돼요. 값만 딱 바꾸시는게 맞아요.
자 이제 예제를 들어볼게요. 만약 Member의 데이터가 변경이 되면 그때는 update를 하고, 변경이 안되면 그때 update 안 할 거야. 라는 코드를 짜는 거에요.
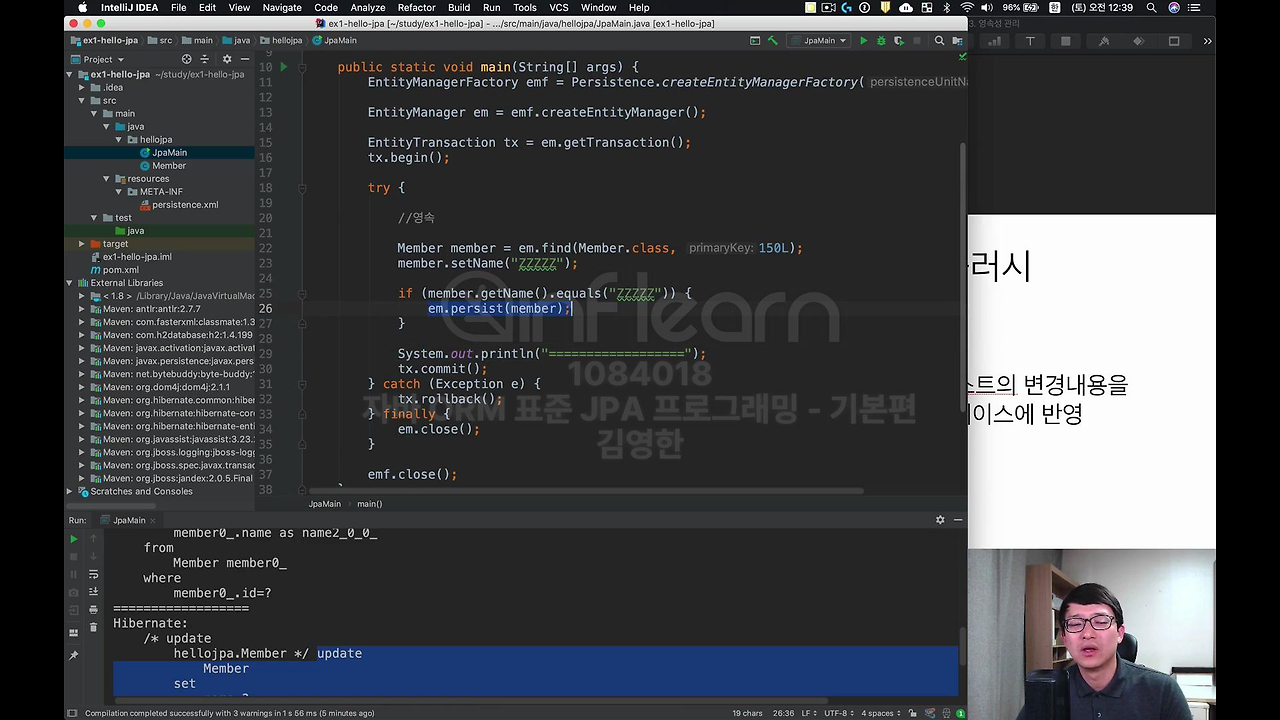
무식하게 만약 'member.getName이 ZZZZ로 변경이 됐어. 이때는 em.persist를 호출해서 Member를 다시 update를 해달라고 요청을 해! 그게 아니면 아무것도 안해!' 라고 코드를 제가 작성한다고 가정을 할게요.

예를 들어서 persist 말고 update를 한다고 고칠게요. 뭐 update 같은 게 있어.
그럼 내 의도는 뭐냐면 뭔가 이 Member가 변경이 된 경우에만 update 쿼리를 날릴 거야. 그게 아닌 경우에 안 날릴 거야. 근데 JPA는 어떻게 동작한다 했죠? 이런 걸 하지 않아도 이미 그냥 무조건 update 쿼리가 날라가요.

혹시라도 이 로직을 잘못 짤 수도 있거든요. 그래서 이렇게 하면 안 되는 거예요.
그냥 '아 jpa는 값을 바꾸면 트랜잭션이 커밋되는 시점에 변경을 반영하는구나' 라고 생각하고 코드를 이렇게 작성하시는 게 맞습니다.
자 그럼 이번엔 넘어가서 flush에 대해서 알아보겠습니다.
'스프링 > 자바 ORM 표준 JPA 프로그래밍 - 기본편' 카테고리의 다른 글
| 준영속 상태 (0) | 2024.05.26 |
|---|---|
| 플러시 (0) | 2024.05.26 |
| 영속성 컨텍스트 1 (0) | 2024.05.25 |
| Hello JPA - 애플리케이션 개발 (0) | 2024.05.25 |
| Hello JPA - 프로젝트 생성 (0) | 2024.05.25 |



