
당니의 개발자 스토리
Hello JPA - 애플리케이션 개발 본문
Hello JPA - 애플리케이션 개발
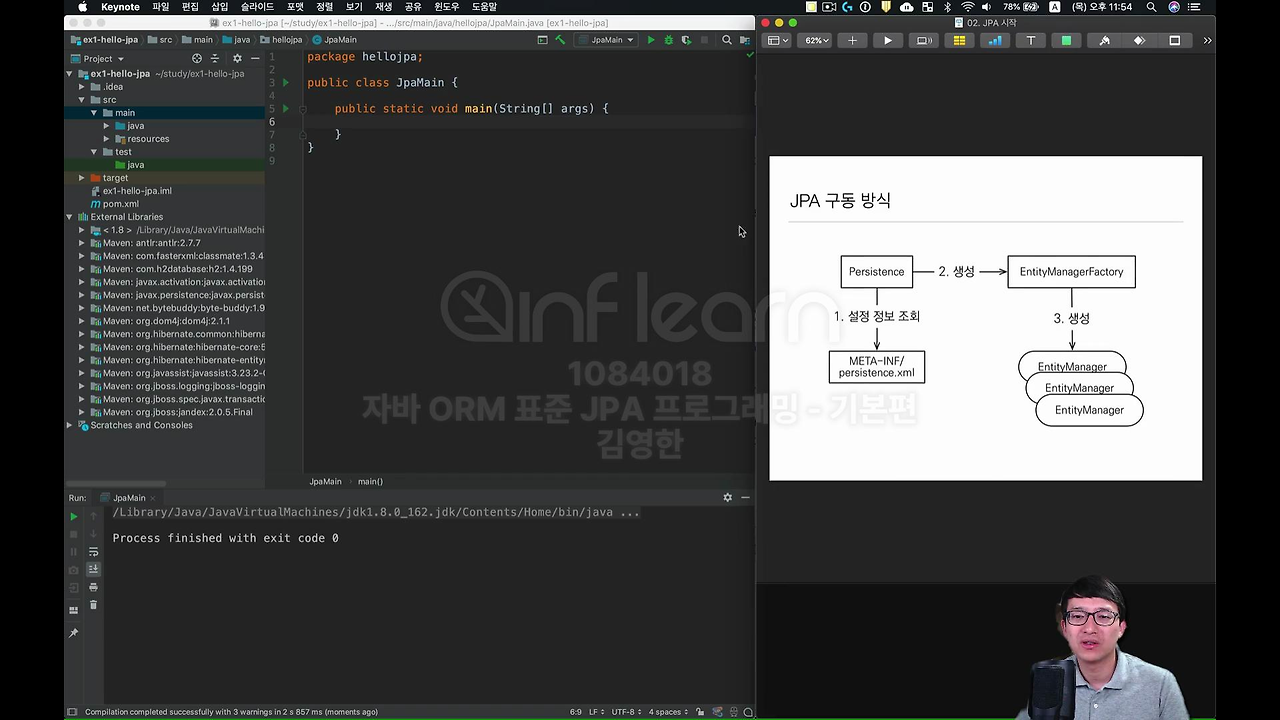
이제 실제 애플리케이션 개발로 넘어가 보겠습니다. 그럼 대체 JPA가 어떻게 동작하냐라는 건데요.

먼저 JPA는 Persistence라는 클래스가 있어요. 일단 Persistence로 시작을 하거든요. 그리고 여기서 방금 우리가 한 Persistence.xml 라는 설정 정보를 읽어서 EntityManagerFactory 라는 클래스를 만듭니다.
그리고 여기에서 뭔가 필요할 때마다 EntityManagerFactory 라는 공장에서 EntityManager라는 걸 찍어내서 돌리면 됩니다.
이제 한번 실습을 해 볼게요.
저는 JpaMain 이라는 클래스를 만들 거고 jpa가 실제 동작하는 걸 한번 보겠습니다.
이렇게 패키지를 만들고 JpaMain 클래스를 만들었으니 시작을 해야 됩니다.
지금 보시면, jakarta의 Persistence 라는 클랙스가 있죠? 이게 안보이면 라이브러리 import가 잘 안 된거예요.
그리고 createEntityManagerFactory 여기에서 보면 재밌는게
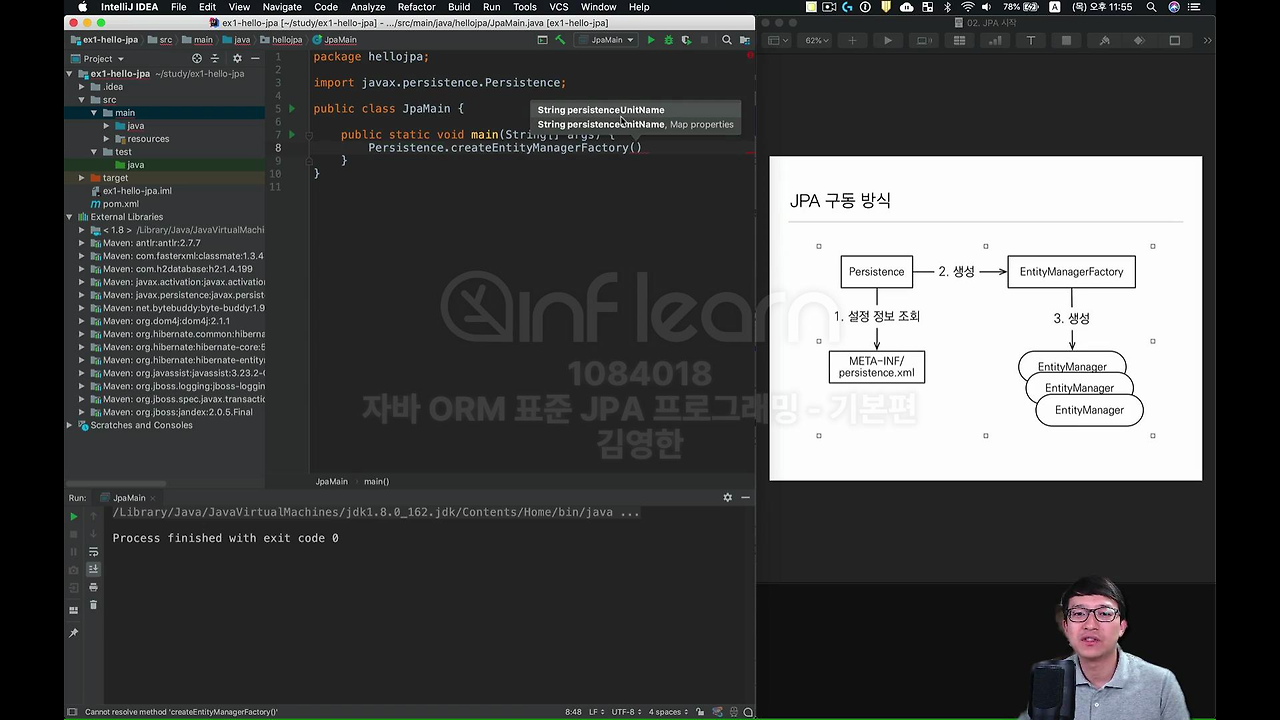
PersistenceUnitName 이라는 걸 넘기라고 합니다.

아까 persistence.xml을 보시면 PersistenceUnit의 name이 있었죠? 아까 우린 hello 라고 적었죠.

이거를 이제 넣어 주시면 됩니다.
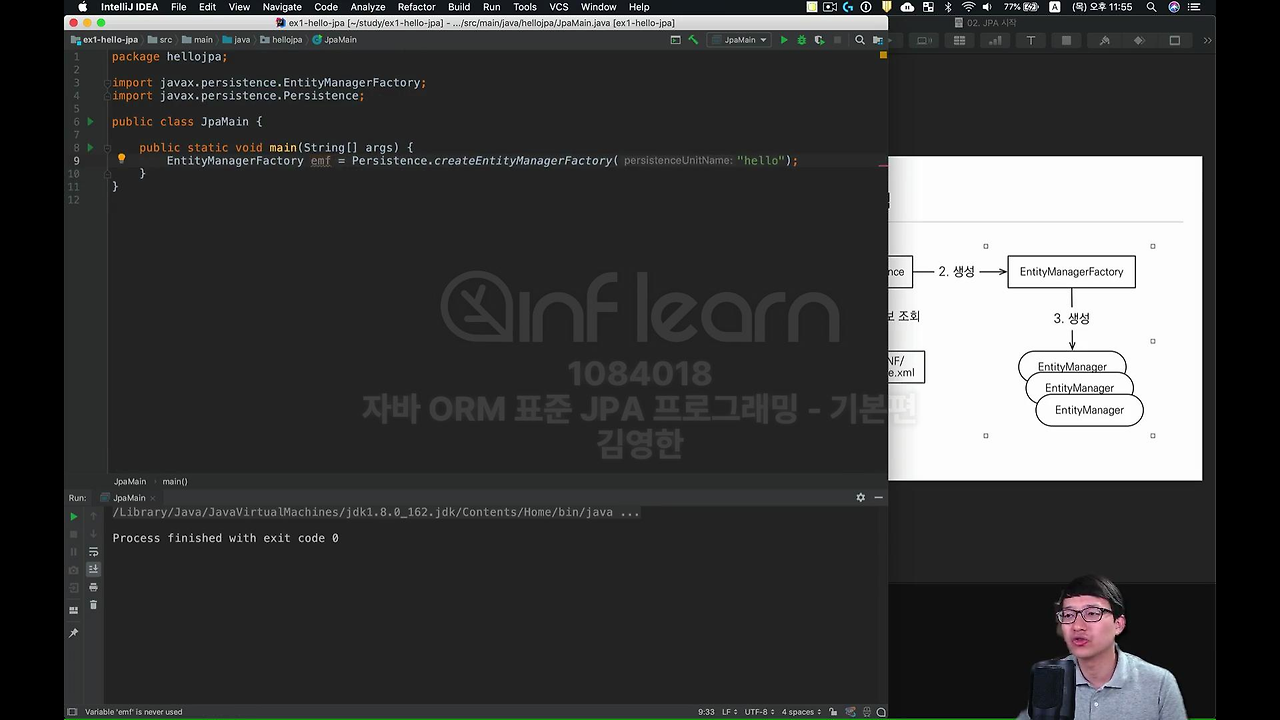
그리고 이제 변수로 받아볼게요. entityManagerFactory 라고 반환을 합니다. 근데 너무 기니까 entityManagerFactory를 그냥 줄여서 emf 라고 쓸게요.
이제 한번 동작하는지 봐야죠. 실행을 해보면,
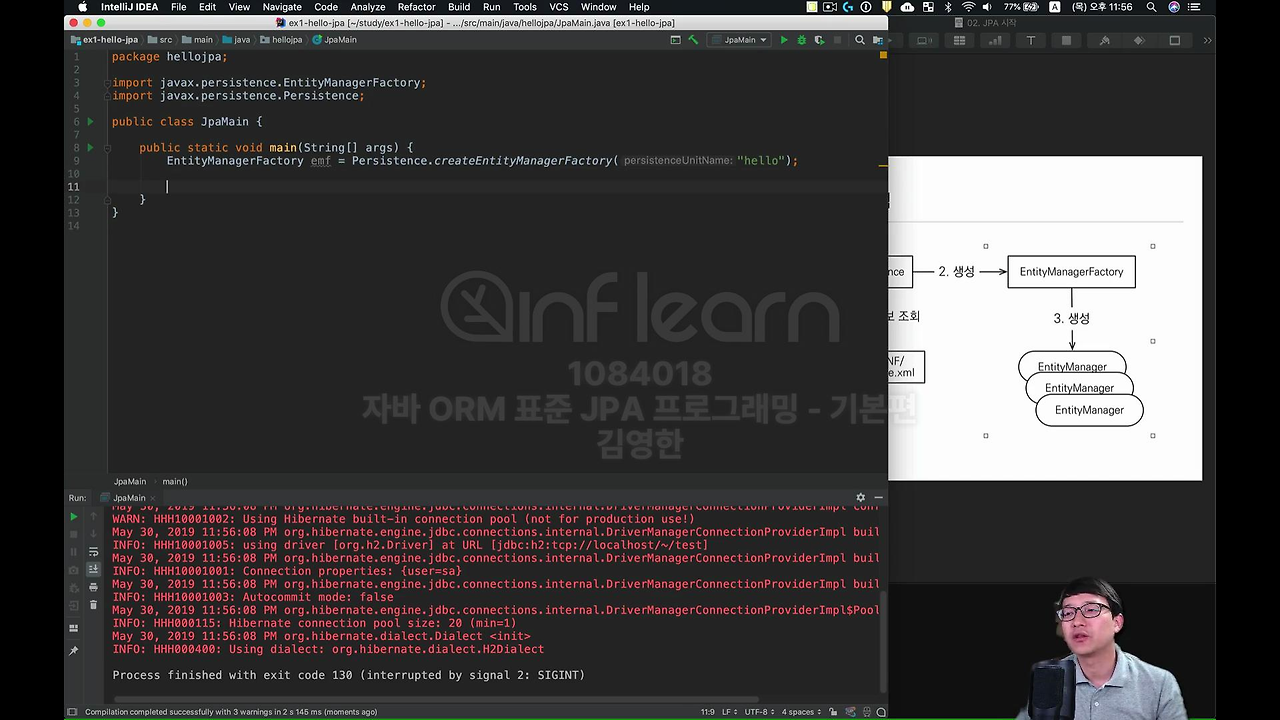
지금 뭔가 빨간불로 쭉쭉 올라가는 게 있죠? 지금 보면 뭔진 모르겠지만 커넥션과 관련된 정보들이 막 동작하고 있죠.

이 EntityManagerFactory를 만드는 순간 뭔가 데이터베이스랑 연결도 다 되고 이제 웬만한게 다 돼요. 그러면 실제 한번 이제 뭐 쿼리라도 날리려면,

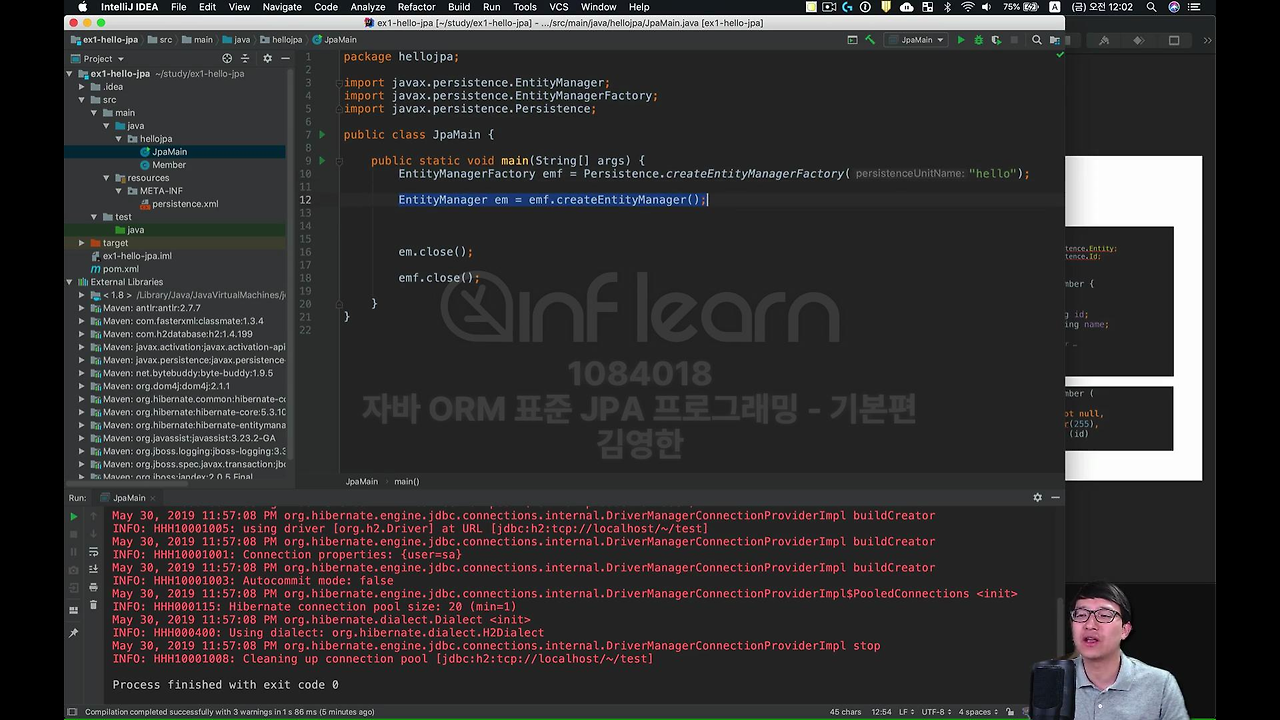
EntityManagerFactory에서 createEntityManager 라는 애를 꺼내야 돼요.
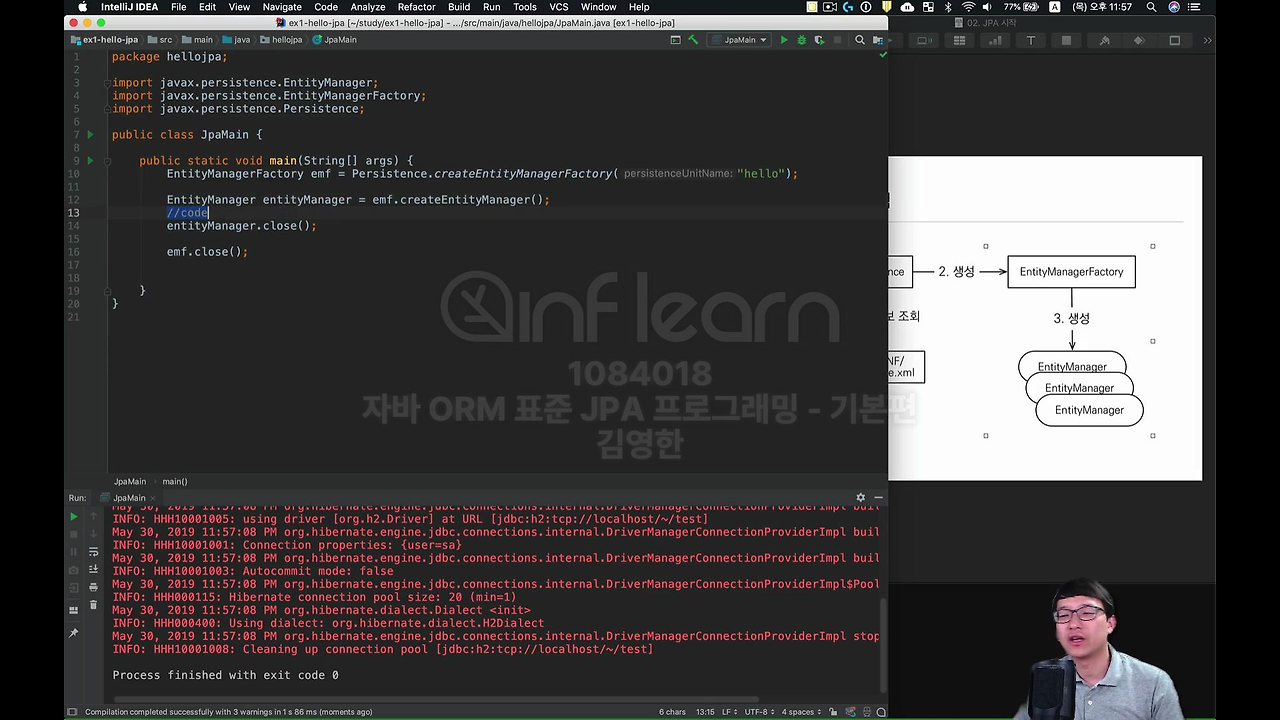
그리고 entityManager.close, emf.close() 해서 잘 끄고 다시 돌려봅시다. 여기서 EntityManager를 꺼내고 이 안에서 실제 우리가 동작하는 코드를 이 // code 에다가 작성하게 됩니다. DB에 데이터를 저장한다던가, 불러온다던가.

그리고 이제 실제 애플리케이션이 완전히 끝나면 이 EntityManagerFactory를 닫아 줘야 됩니다. EntityManager를 em으로 줄여서 쓸게요. 근데 지금 뭐라도 만들어야 DB에 넣고 빼고 할 수 있겠죠.

이제 밑에 테이블 보이시죠. Member라는 테이블을 한번 만들어 보겠습니다. 테이블을 만들어서 실제 맵핑을 해야 뭔가 jpa가 코드를 짜서 동작해 볼 수 있겠죠.

여기서 이 url이 되게 중요해요. 이 jdbc url은
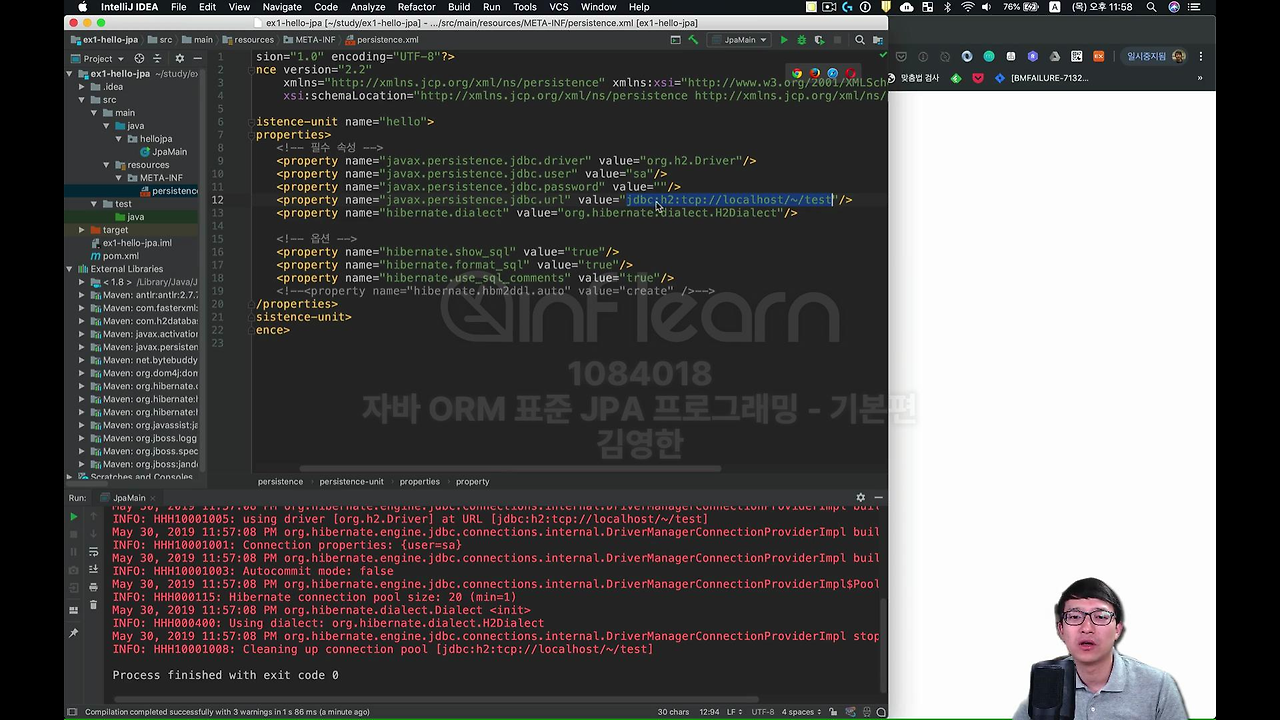
여기 설정 파일을 넣었던 거죠. 이거랑 똑같이 맞추셔야 됩니다.
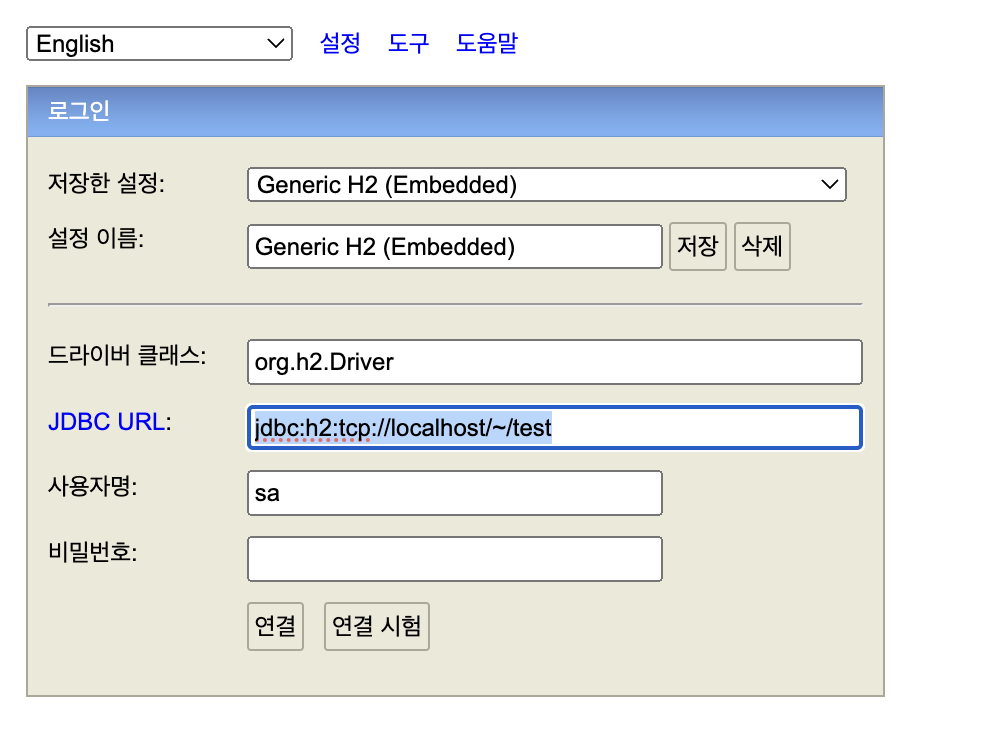
그래서 연결 하면,
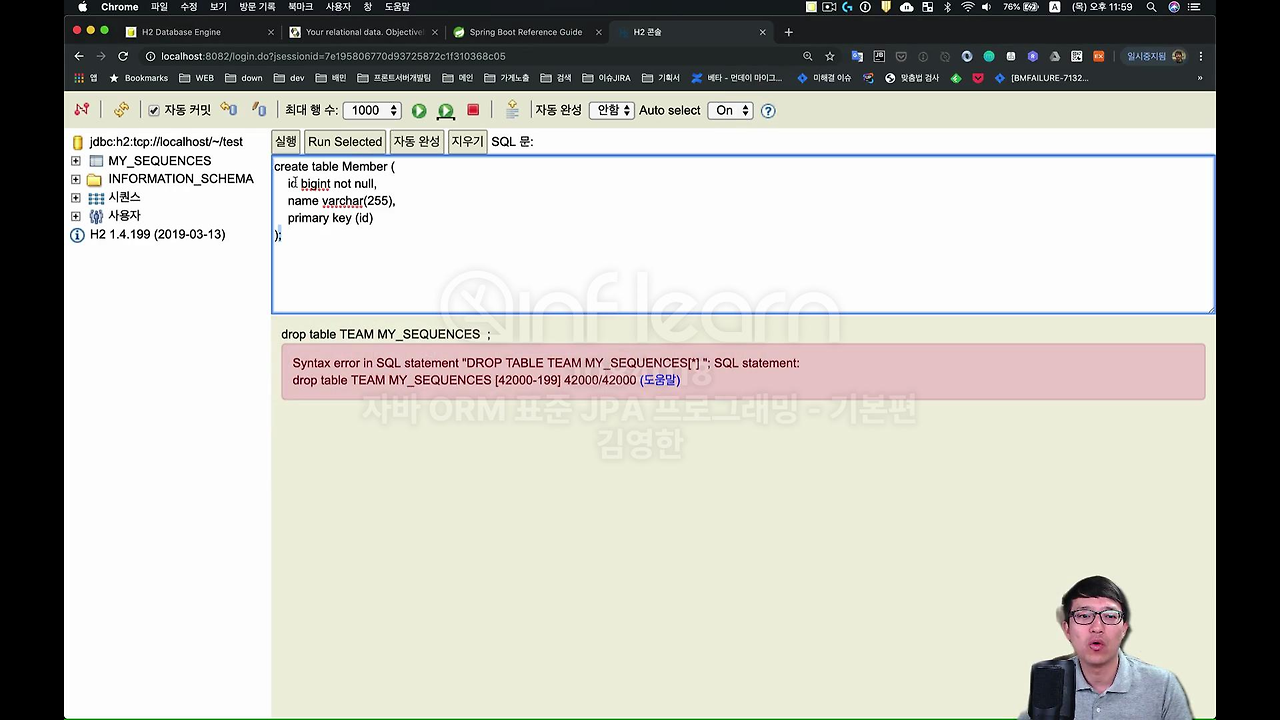
이제 테이블을 만들어야 되겠죠. Member고 id 는 bigint의 not null 이고, 이제 그냥 이름 딱 하나만 있는 거에요. varchar(255)고 pk는 id입니다. 그래서 딱 만들면 테이블이 만들어졌겠죠.
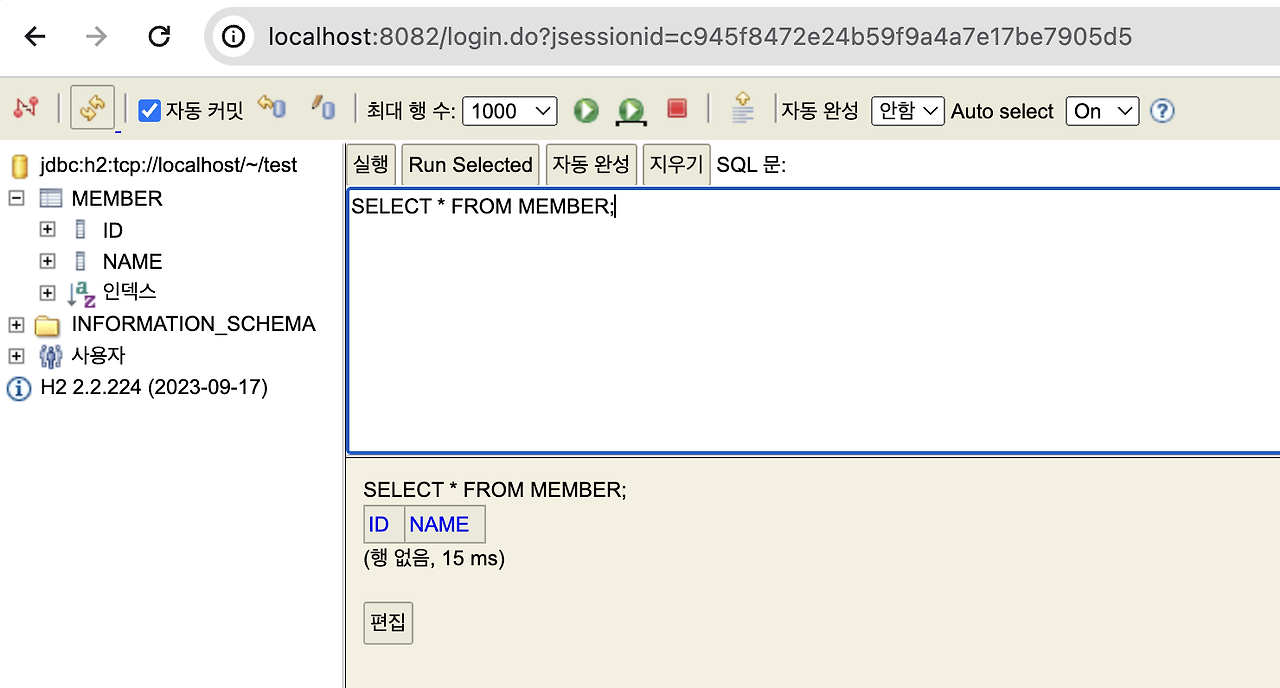
이게 아무것도 없는 상태에서 쿼리를 간단히 실행을 해보면 select 쿼리가 나가면서 id랑 name이 보이죠.

그리고 이제부터 방금 우리가 만든 테이블이랑 맵핑이 되는 Member라는 클래스를 만들 거에요.

여기에다가 만드시고,

우선 jakarta.persistence.Entity를 꼭 넣으셔야 됩니다. 그래야 jpa가 처음 로딩될 때 'jpa를 사용하는 애구나' 라고 인식을 하고 이거는 jpa가 '내가 관리해야 되겠다'라고 인식을 하게 됩니다.

그리고 나서, 왜 이 왜 두 가지 필드를 넣었냐면 id랑 name이 db에 있으니까 맵핑하기 위해서 넣어준 겁니다.
그런데 여기서 JPA한테 PK가 뭔지는 알려줘야 돼요.

그래서 jakarta.persistence.Id를 넣어줍니다.

그 다음에 이제 필요한 Getter, Setter 들을 만들어야죠. 우선은 Getter, Setter를 cmd + N 해서 다 만들겠습니다.

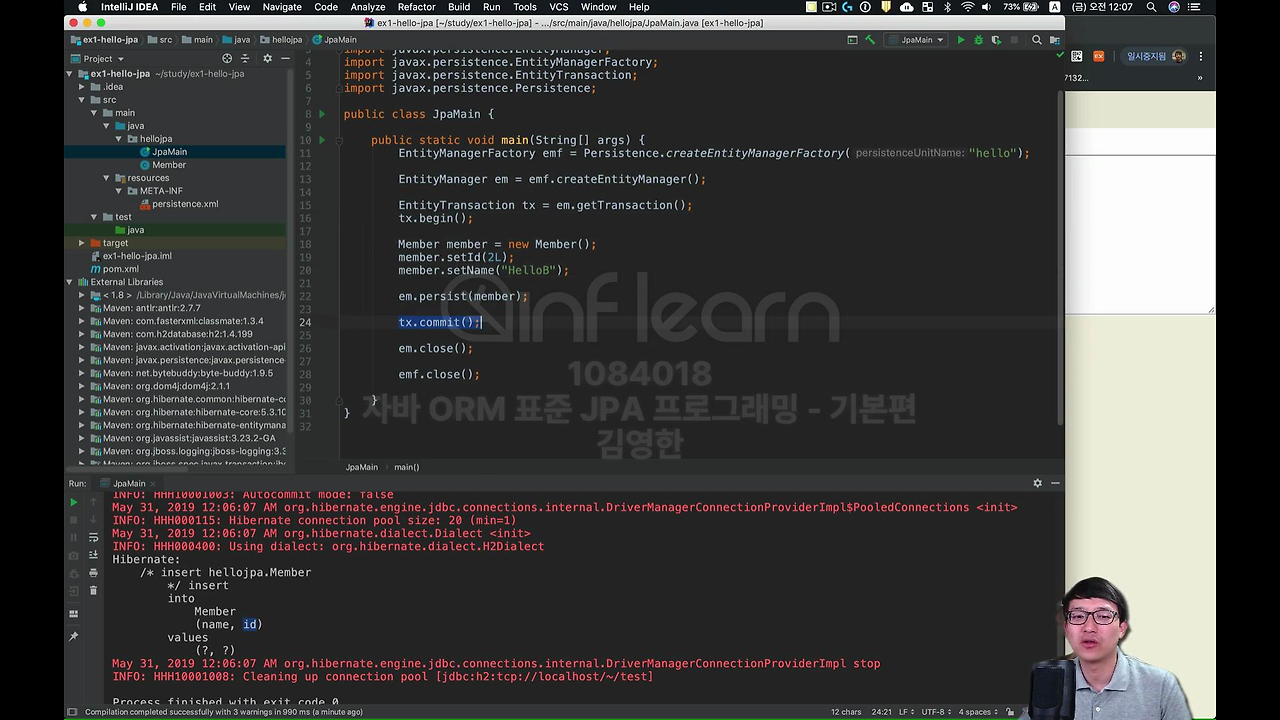
자 그러면 실제 Member를 한번 저장해 보겠습니다.

어떻게 하면 되냐면 이제 코드를 넣어야 되는데 이 EntityManagerFactory는 애플리케이션 로딩 시점에 딱 하나만 만들어 놔야 돼요.
그리고 실제 내가 DB에 저장하거나 하는 트랜잭션 단위 있잖아요. 예를 들어서 고객이 들어와서 행위를 하고 나가고, 또 고객이 어떤 상품을 장바구니에 담았다라던가 이런 걸 할 때마다 뭘 해줘야 되냐면 DB 커넥션을 얻어서 쿼리를 날리고 종료되는, 어떤 하나의 일관적인 단위를 할 때마다
이 EntityManager라는 애를 꼭 만들어 주셔야 됩니다.

member를 만들고, 어떻게 저장해야 되냐면 em.persist 해가지고 Member를 넣으시면 됩니다. 그러면 저장이 됩니다.
실행을 해보면,
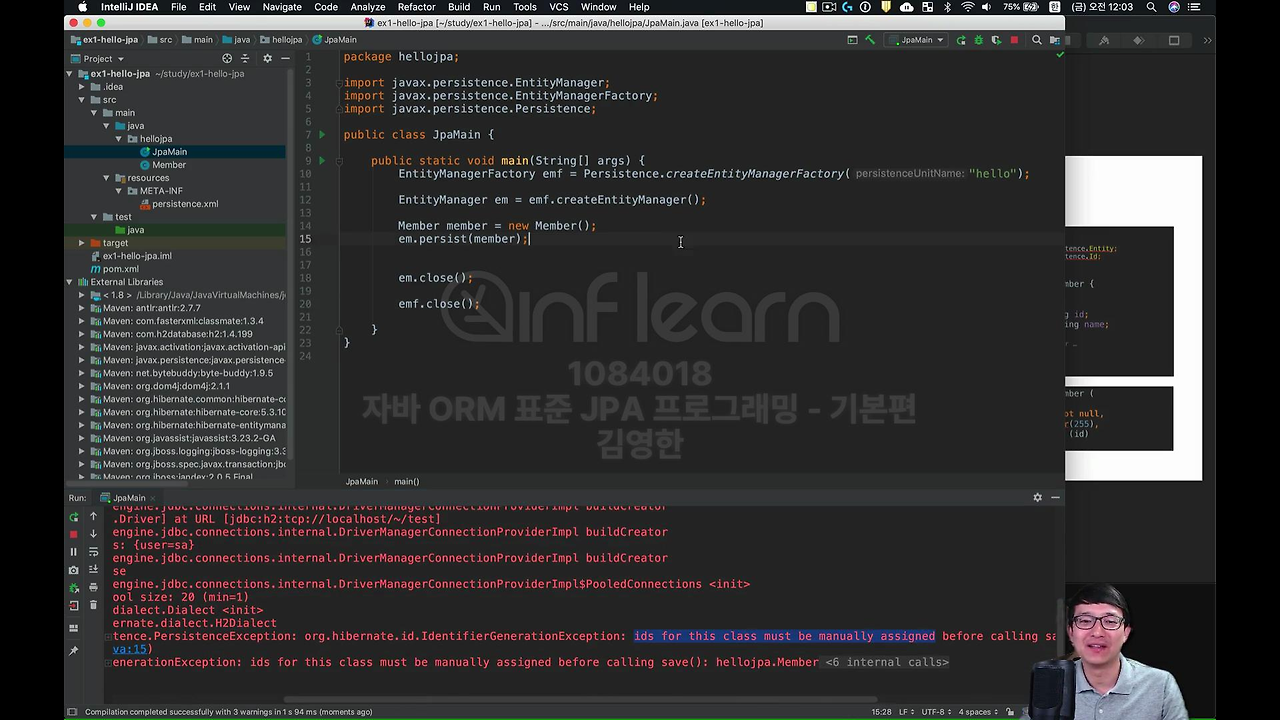
id가 없다고 하죠.

그래서 이렇게 해서 실행을 하면 이번 것도 에러가 나긴 할 거예요. 여기서 id에 붙은 L은 Long을 표현한 겁니다.

자 돌려보면 뭔가 된 것 같지가 않아요.
왜 그러냐면 JPA에서는 꼭 transaction 이라는 단위가 엄청 중요해요. 모든 데이터를 변경하는 모든 작업은 JPA의 transaction 안에서 꼭 작업을 해야됩니다. 그래서 이거를 어떻게 해야 되냐면,
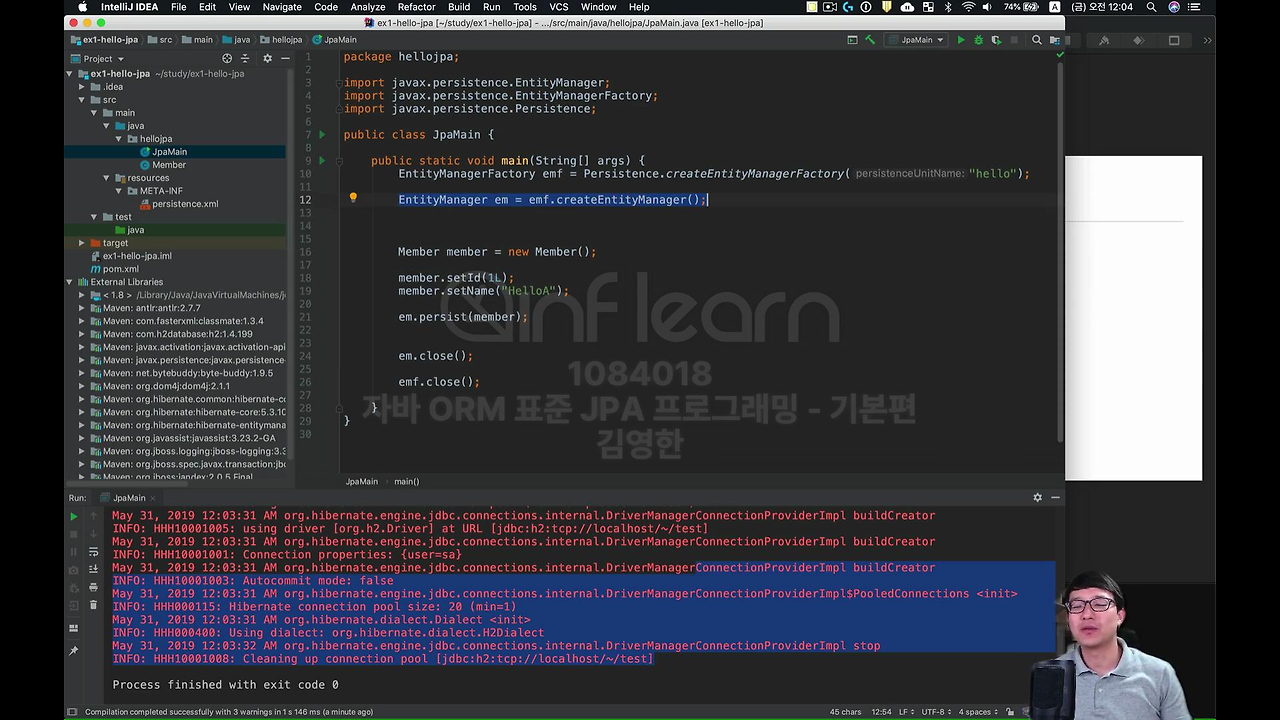
일단 EntityManager를 제가 받았죠. 쉽게 생각하면 그냥 데이터베이스의 커넥션을 하나 받았다고 생각하시면 돼요.

그럼 여기서 em.getTransaction 이라고 해서 이걸 호출하시면 트랜잭션을 얻을 수 있습니다.
제가 축약으로 tx 라고 할게요. 그 다음에 tx를 시작해야 되겠죠.

begin 하시면 그럼 이제 데이터베이스 트랜잭션을 딱 시작을 합니다.
그리고 트랜잭션이 끝나면 어떻게 해야될까요?

지금 보시면 이 logic이 만들고 JPA에 저장하고 그 다음에 commit 해야 되겠죠?

그래서 tx.commit 해주시면 커밋이 딱 됩니다.
커밋은 작업 내용을 db에 반영하는 행위이며, 롤백은 작업 내용을 이전 상태로 되돌리는 행위입니다.
커밋을 해야 작성한 코드가 최종적으로 db까지 반영할 수 있다고 보면 됩니다.
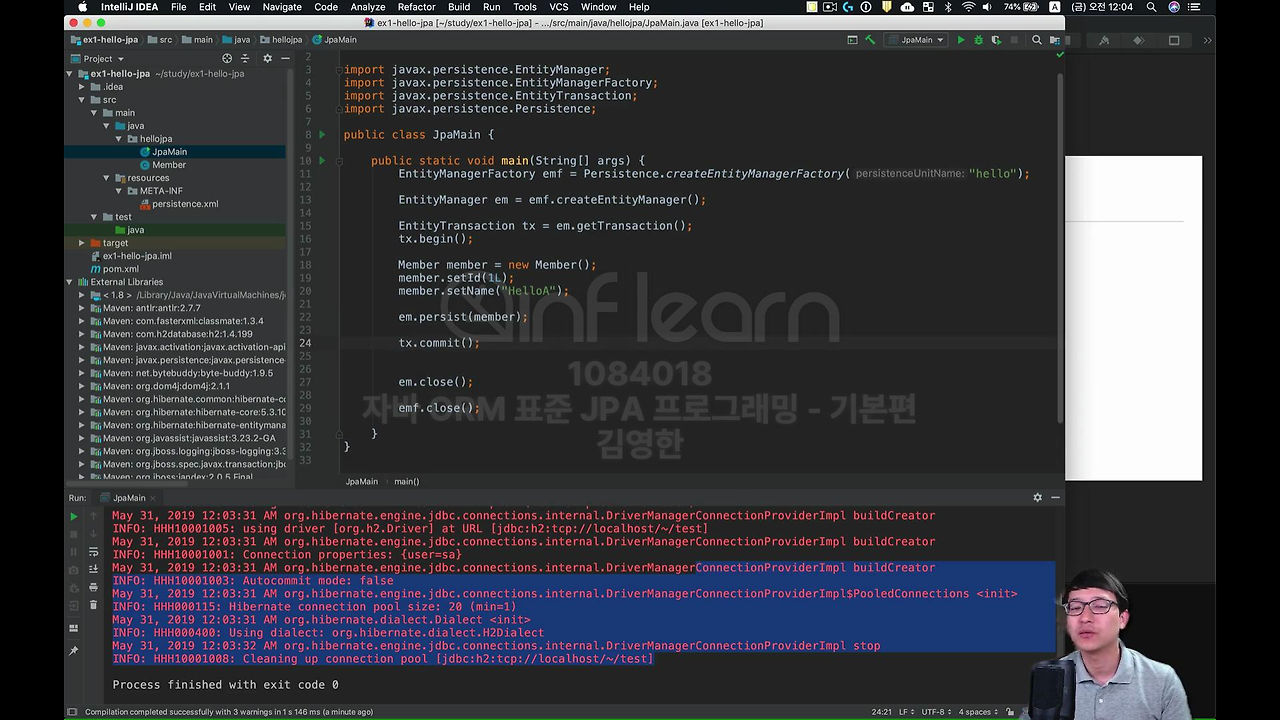
그래서 만약 문제가 생기면 rollback 이런 것들 해야 되겠죠? 이건 나중에 하고 우선 실행해 볼게요.
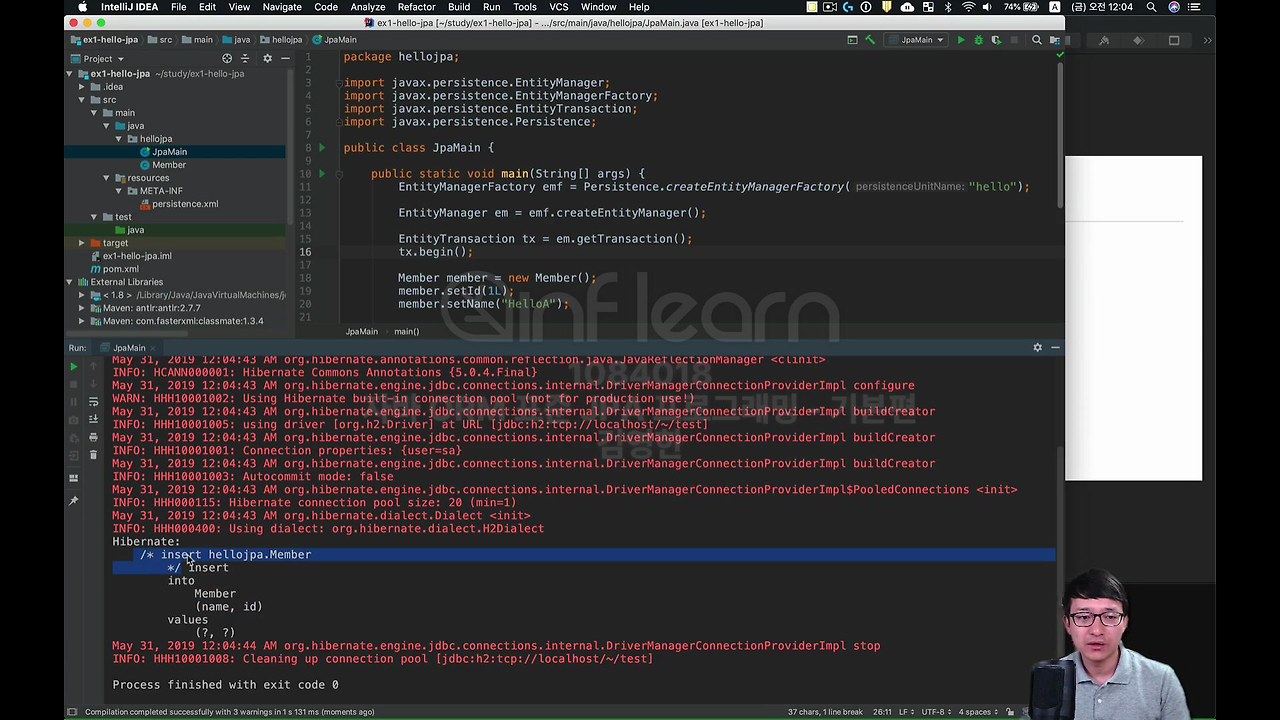
이제 드디어 여기 보시면 지금 query가 나갔죠? insert into 뭐 뭐 뭐 나갔죠? 일단 드래그 한 부분은 주석입니다. hellojpa.Member가 insert가 되었다는 주석이 있고,
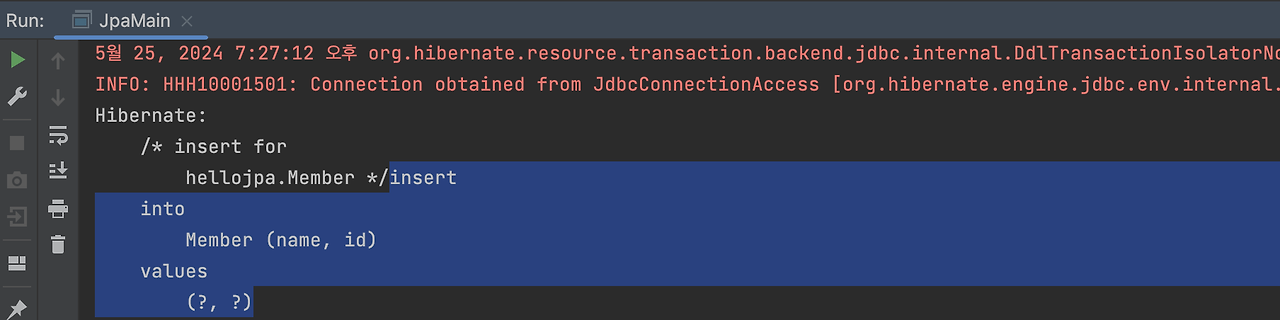
그 뒤에 실제 쿼리가 나간거죠.
이것은 왜 이렇게 찍히냐면 설정에서 보시면
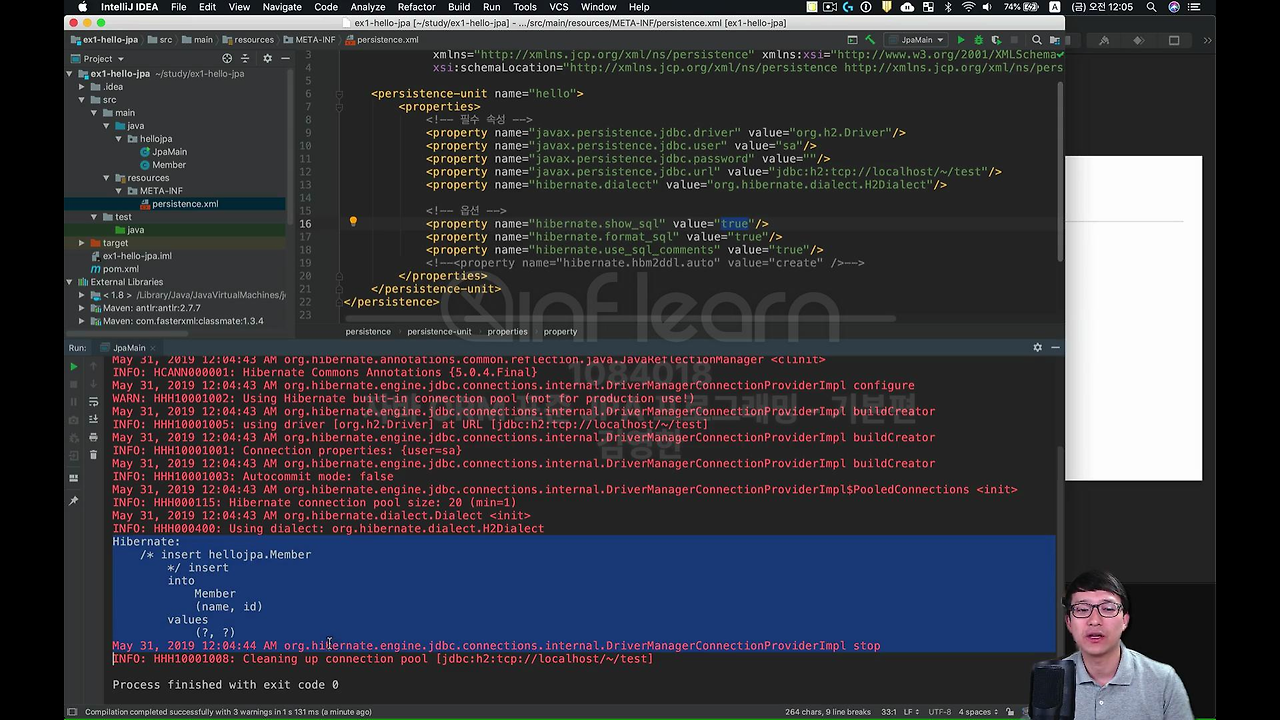
hibernate.show_sql 하면 이 Query가 println으로 보이는 거구요.
hibernate.format_sql 하면,

이렇게 예쁘게 포맷팅을 해줍니다.
그 다음에 hibernate.use_sql_comments란 건 뭐냐면,
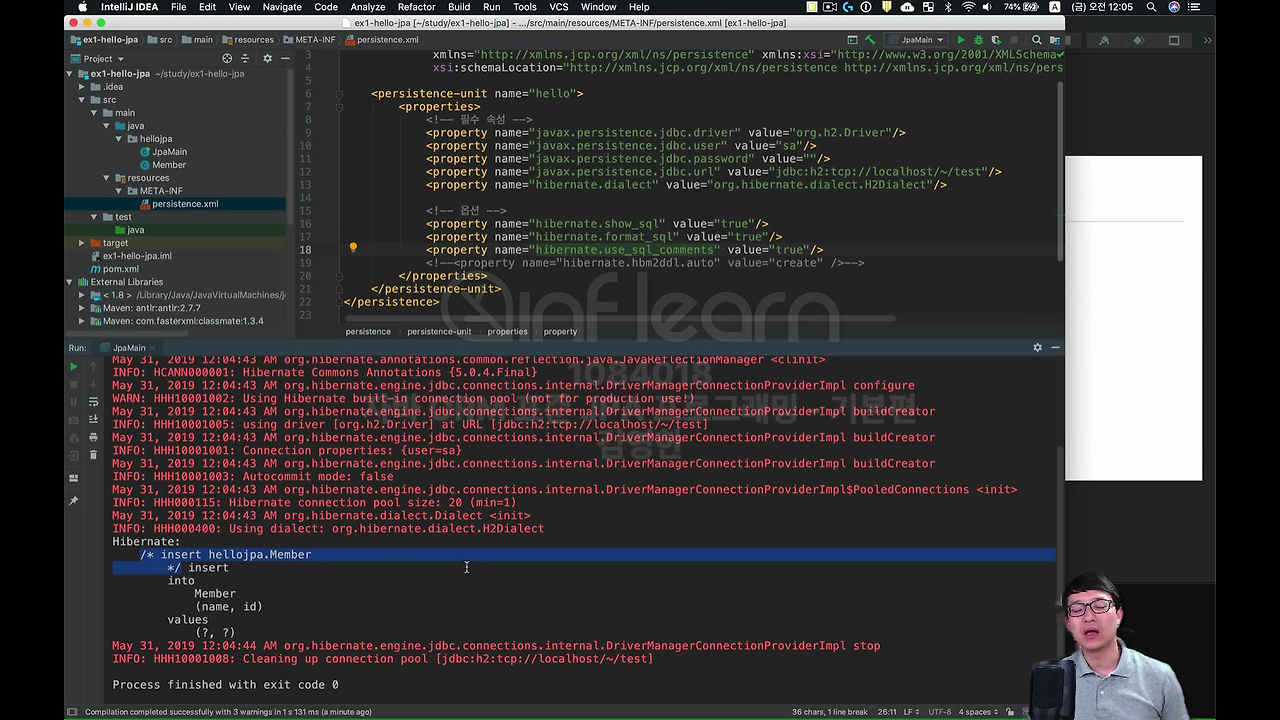
이겁니다. 그러니까 '이 Query가 왜 나온 거야?' 라고 알려주는 거죠. 그럼 뭔가 '사용자가 Member를 insert 했어. jpa가 Member를 insert 해가주고 이 쿼리가 나온 거야' 라고 이제 주석이 나온 겁니다.

그럼 이제 실제 db에 한번 가볼게요. 데이터 정말 저장이 되었나 보겠습니다.

select 쿼리를 실행해보면 여기 저장이 되어있죠.

이번에는 id를 2번으로 바꾸고 helloB로 해볼게요.
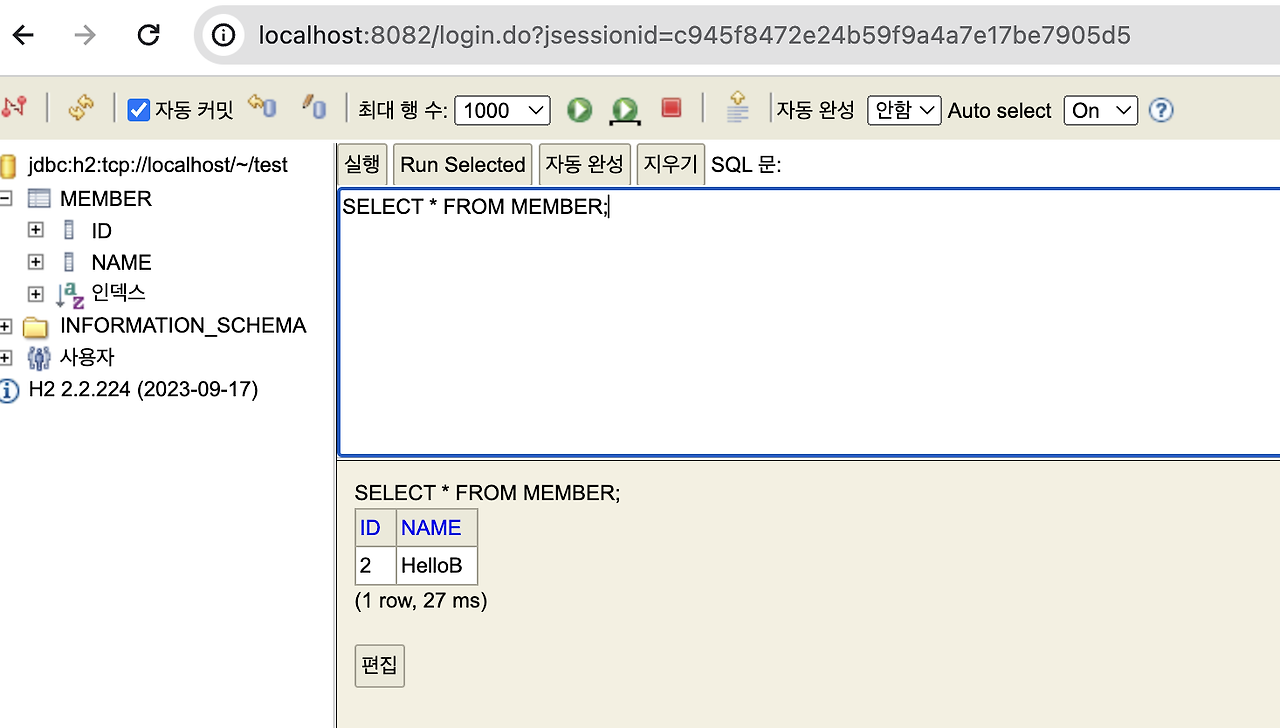
실행하면 이렇게 잘 나옵니다.
사실 김영한t 강의에서는 Id 1과 Id 2인 Member가 둘 다 나오는데,

김영한t는 이 한 줄을 주석처리 했기 때문이다. 나는 create로 해놨기 때문에 기존 테이블을 삭제한 다음 다시 생성된다.
ddl-auto 옵션 종류


지금 잘 보시면 제가 쿼리를 직접 만든 게 없어요. JPA가 이 맵핑 정보를 보고 자기가 딱 넣어주는 거예요. 어? 근데 좀 이상하죠? '이상하다! 내가 Member를 어느 테이블에 저장하라고 따로 말한 적이 없는데?'
사실 이제 관례를 따른 겁니다. 아무것도 안 적혀있으면 클래스 이름과 동일한 테이블로 가는 거겠죠.
그럼 Member랑 테이블 이름이 다를 수 있잖아요. 만약 데이터베이스에 Member가 아니고 USER 라는 테이블이 있어요.

그러면 이렇게 맵핑 해주시면 돼요. 그러면 query가 나갈 때 user라는 테이블에 insert 하라고 나갑니다.
그리고 다음 시간에 설명드리겠지만, 예를 들어서 column name이 db는 username 이라고 하면,

이렇게 맵핑을 해주면 돼요.
그렇게 하면 db에 insert into query가 나갈 때 여기가 name, id가 아니고 username, id로 나가는 거죠. 이렇게 해서 Annotation에다가 필요한 맵핑을 다 하시면 됩니다.
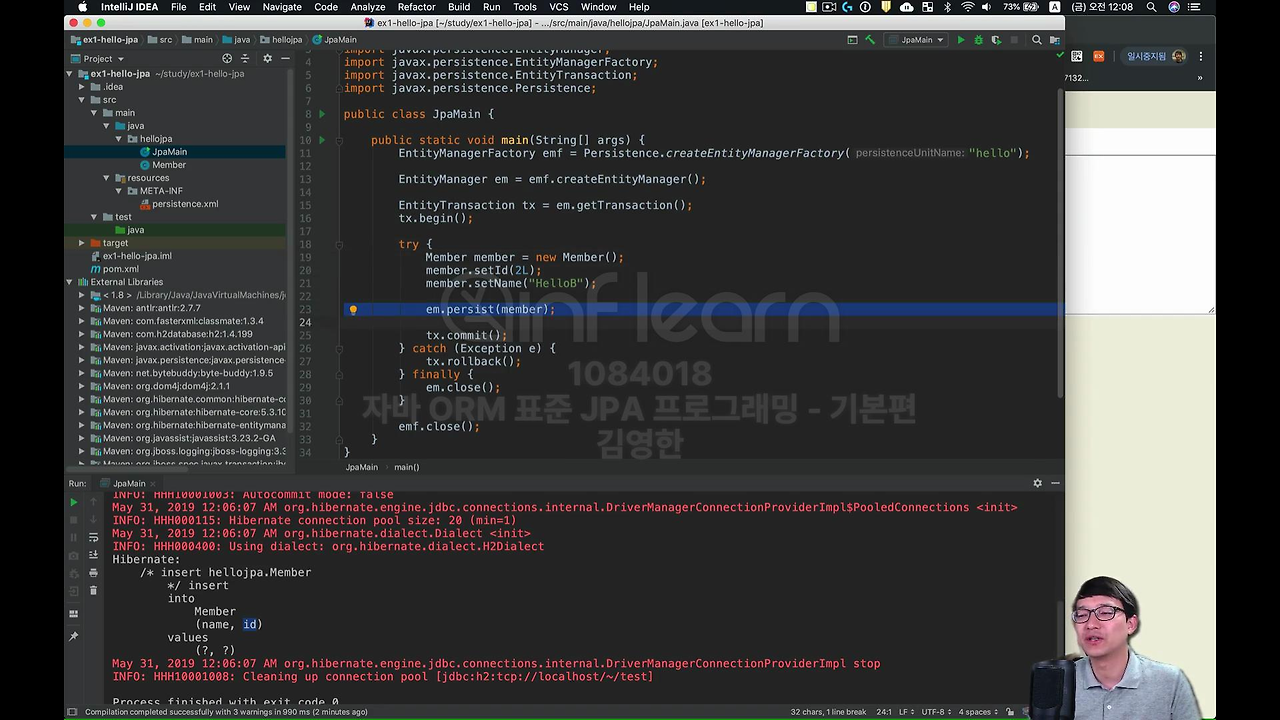
지금 코드를 보면 잘 했는데 만약에 문제가 생기면 좀 안 좋은 코드죠.
왜냐하면 예를 들어서 em.persist(member)에서 문제가 생기거나 tx.commit() 에서 문제가 생겼을 때

em.close();도 호출이 안 되고 emf.close();도 호출이 안돼요.
그래서 정석 코드는 이렇게 짜야 되죠.

뭔가 트랜잭션을 try-catch 안에다가 해서 catch exception으로 정상적일 때는 커밋을 하고 문제가 생기면 이렇게 롤백 해줍니다. 그 다음에 finally에서는 작업이 다 끝나면 EntityManager를 닫아줘야 되는데 이게 되게 중요해요.
EntityManager가 결국 내부적으로 데이터베이스 커넥션을 물고 동작하거든요. 그렇기 때문에 이걸 꼭 닫아주셔야 돼요. 그리고 전체 애플리케이션이 끝나면 EntityManagerFactory까지 닫아주는 거까지가 정석 코드인 거죠.
보통 이런 정석 코드대로 하시면 되는데 사실은 첫 시간이고 JPA를 정석으로 쓰는 거 보여드리기 위해서 이렇게 한 거고 실제 이제는 이런 코드가 다 없어지죠.
왜냐? 다 스프링이 다 해주니까.
그래서 그냥 em.persist(member) 정도만 호출하면 끝나는 거죠.
자 그러면 만약에 수정하려면 어떻게 해야 되냐? 수정 한번 해볼게요.
이 코드는 그냥 지우고요.

제가 이 EntityManager에다가 find 라고 해요. 그래서 이 EntityManager를 마치 Java 컬렉션처럼 이해하시면 돼요. 뭔가 내 객체를 대신 저장해 주는 녀석이라고 생각하면 돼요.

그럼 첫번째 파라미터가 엔티티 클래스죠? 그래서 Member.class 적어주시고, PK가 뭐죠? '난 1L 첫번째 찾아올거야' 하면 이 Member를 찾아올 수가 있습니다.
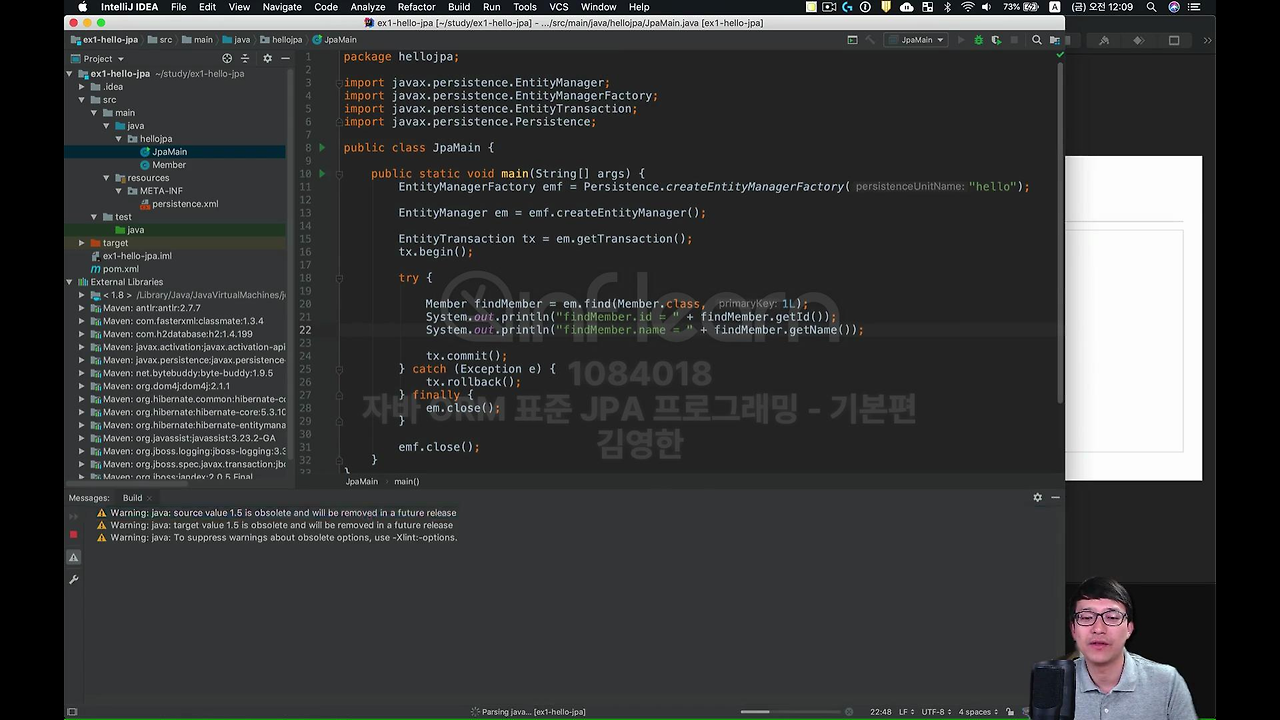
잘 찾아왔는지 출력해 볼게요. 돌려보시면,

여기에 select query가 나갔죠.
그리고 밑에 출력물 보시면 id는 1, name은 HelloA 라고 정확하게 조회가 됐죠. 자 이렇게 해서 조회를 하시면 되고 그럼 삭제는 어떻게 하면 되냐면,
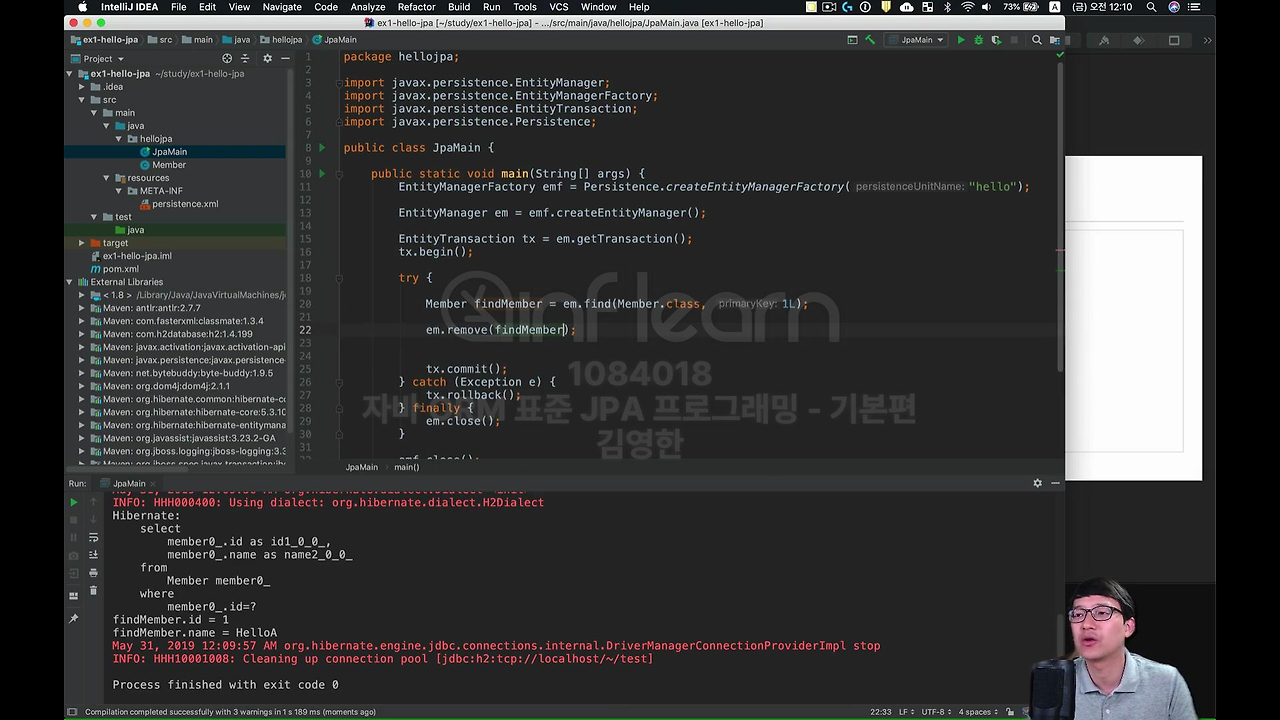
em.remove 라고 있어요. 여기다가 찾은 Member를 넣어 주시면 돼요. 그러면 delete 쿼리가 나가면서 삭제가 됩니다.
자 그 다음에 수정이 아주 기가 막힌 데요.

보시면 방금 Member를 찾았단 말이에요. 근데 내가 이름을 setName 해서 바꿔요. 그래서 이름을 HelloA에서 HelloJPA로 바꿨어요. 그러면 '어? 그럼 다시 저장해야 되는 거 아닌가요?, em.persist(findMember) 해서 다시 저장해야 되지 않나요?'
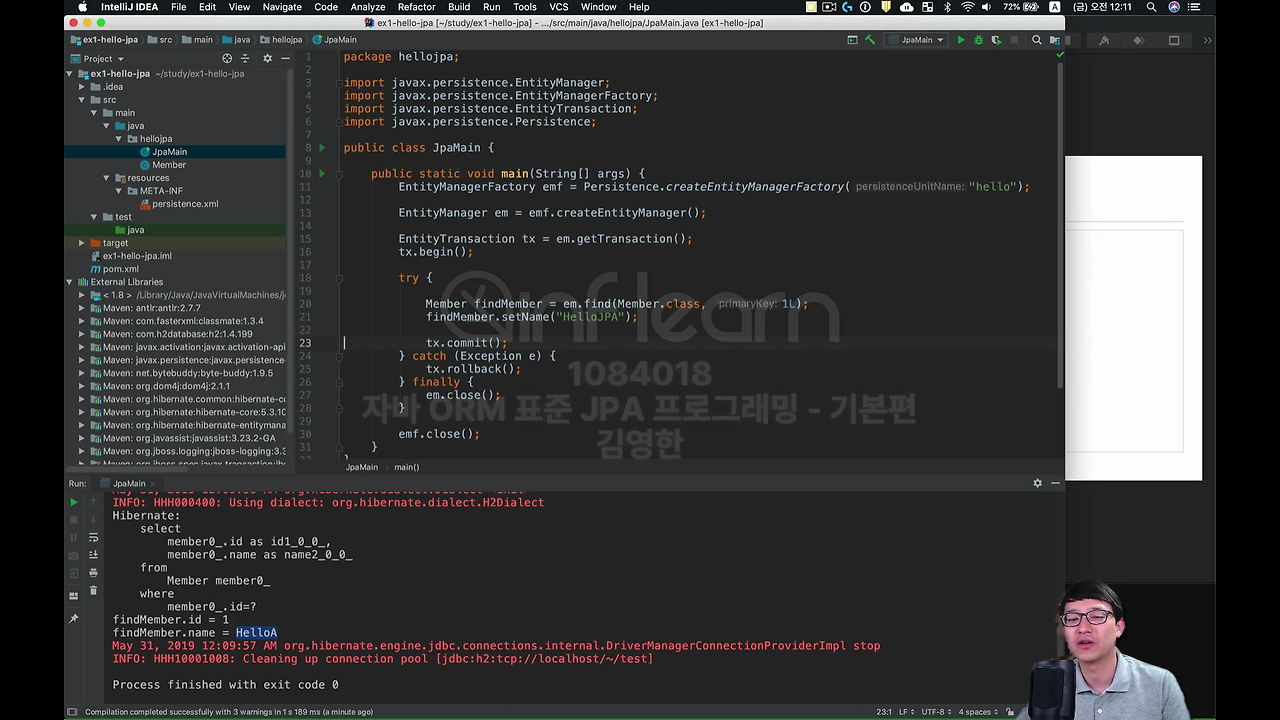
저장 안해도 됩니다. 왜 안 해도 되냐면 우리가 마치 Java Collection을 다루는 것처럼 다루도록 설계된 거라서 그래요.
돌려보면,
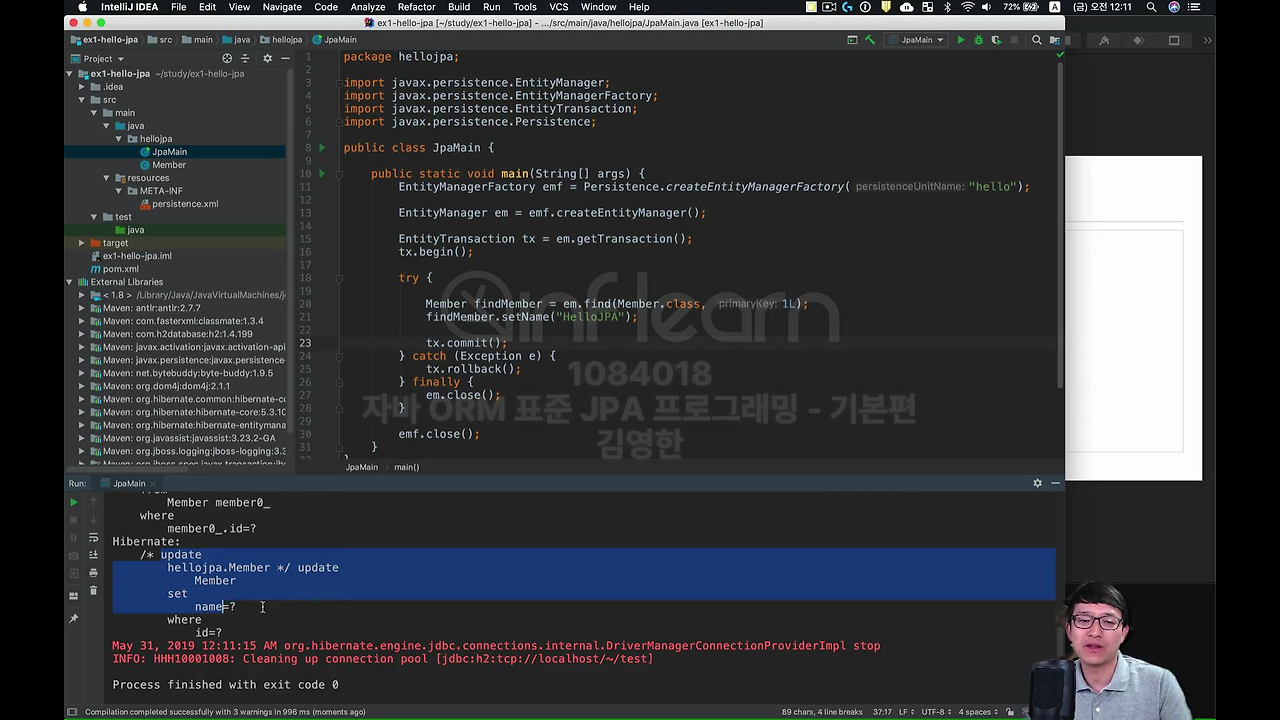
update 쿼리가 나간 게 보이실 거에요.
실제 데이터베이스에 바뀌었는지 볼게요.
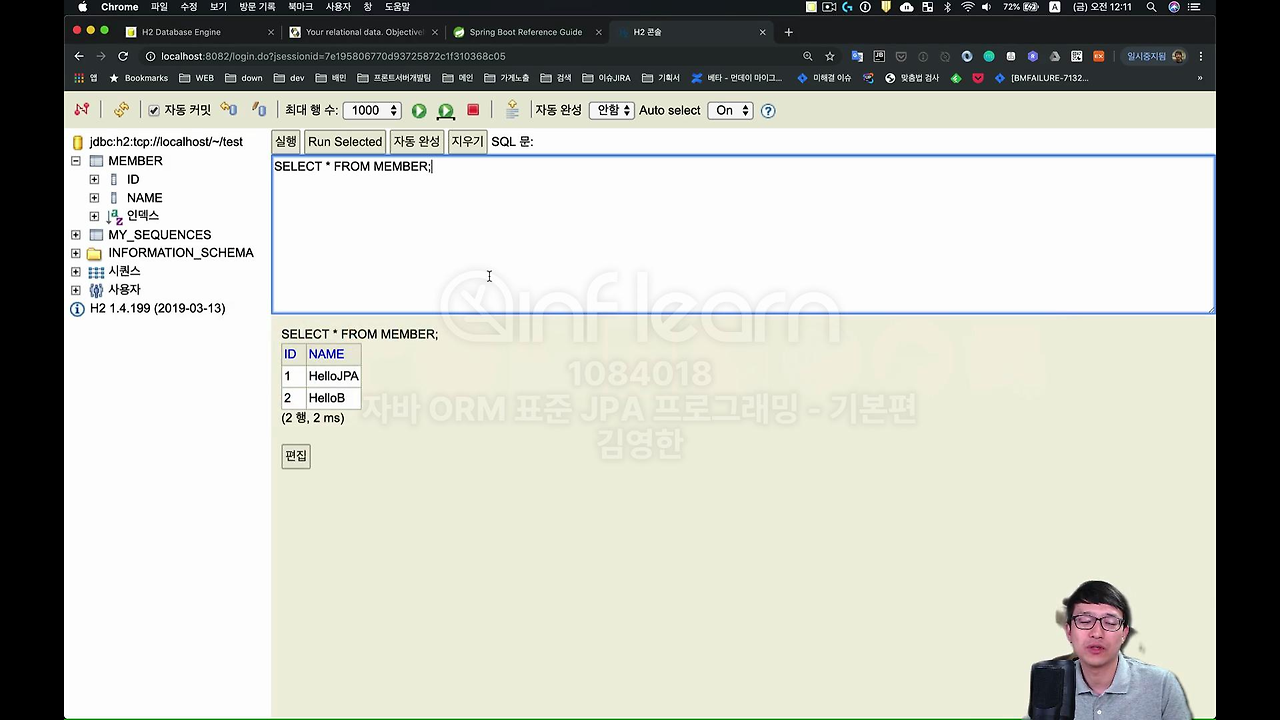
잘 바꼈습니다. '이상하다? 어떻게 Java 객체를 값만 바꾸고 말았는데 이게 어떻게 되는 거지?'
왜 그러냐면 JPA를 통해서 이렇게 엔티티를 가져오면 findMember는 JPA가 관리를 합니다. 그리고 JPA가 뭔가 변경이 됐는지, 안 됐는지 트랜잭션을 커밋하는 시점에 다 체크를 해요. 그래서 얘가 뭔가 바뀌었네 하면 update 쿼리를 만들어서 날립니다.
트랜잭션 커밋하기 직전에 update 쿼리를 만들어서 날리고 트랜잭션이 딱 커밋이 됩니다.
아무튼 그래서 이번 강의의 목표 자체가 이런 것들을 여러분들이 도대체 어떤 메커니즘으로 동작하고 어떤 이유로 이런 식으로 설계했는지, 이거 자체를 되게 자세히 설명을 드릴 거예요.
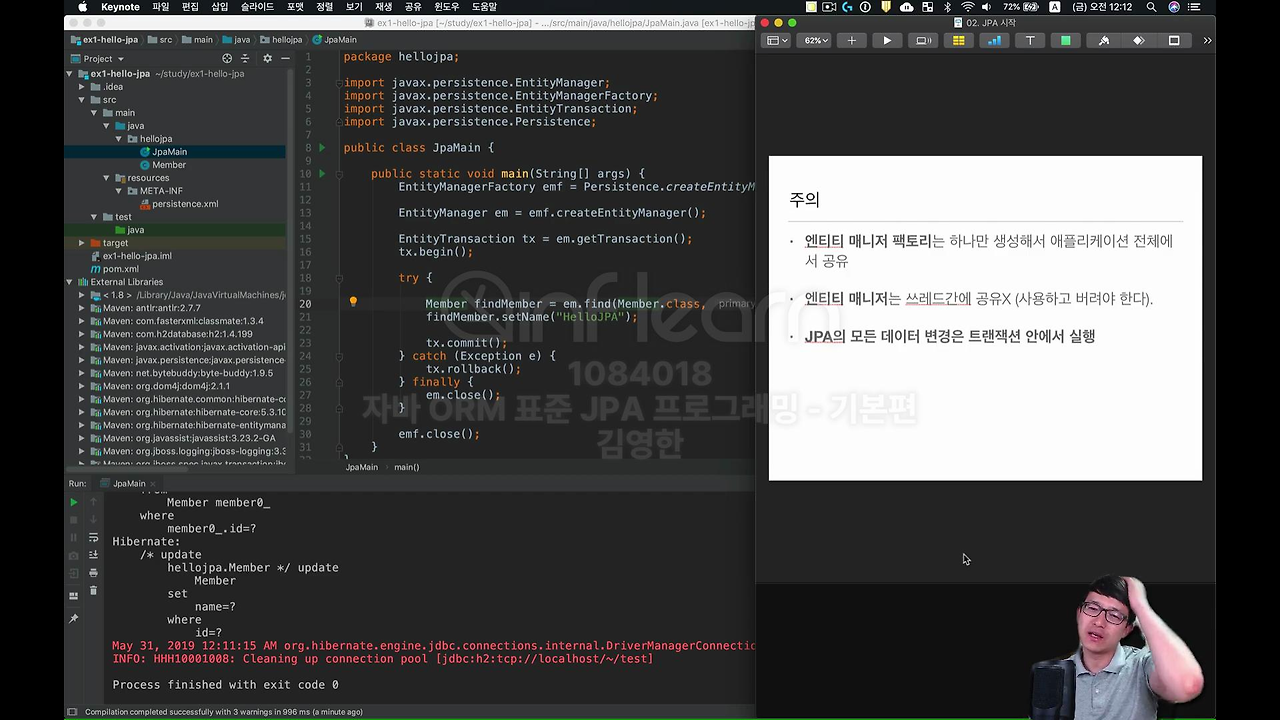
자 그럼 이제 다 해봤고 주의를 보시면,

이제 방금 말씀드린 EntityManagerFactory 라는 것은 여러분이 웹 애플리케이션 서비스를 한다고 하면 웹 서버가 올라오는 시점에 딱 하나만 생성이 되는 거예요. 그래서 DB당 하나만 생성이 되고,

그 다음에 이 EntityManagerFactory에서 EntityManager라는 것은 고객의 요청이 올 때마다 계속 썼다가 em.close()로 버렸다가 이렇게 동작하신다고 보면 돼요.

그래서 이제 조심해야 될 것은 이 EntityManager는 Thread 간에 절대 공유하시면 안 돼요. EntityManager를 하나 만들어서 여러 쓰레드에서 같이 쓴다? 망해요. 왜냐하면 EntityManager 라는 건 사용하고 버려야 되는 거예요. 마치 우리가 데이터베이스 커넥션을 빨리 쓰고 바로 버리잖아요. 그니까 돌려주잖아요. 그런 것처럼 쓰고 버려야 됩니다.
그리고 이거 정말 중요한데요.
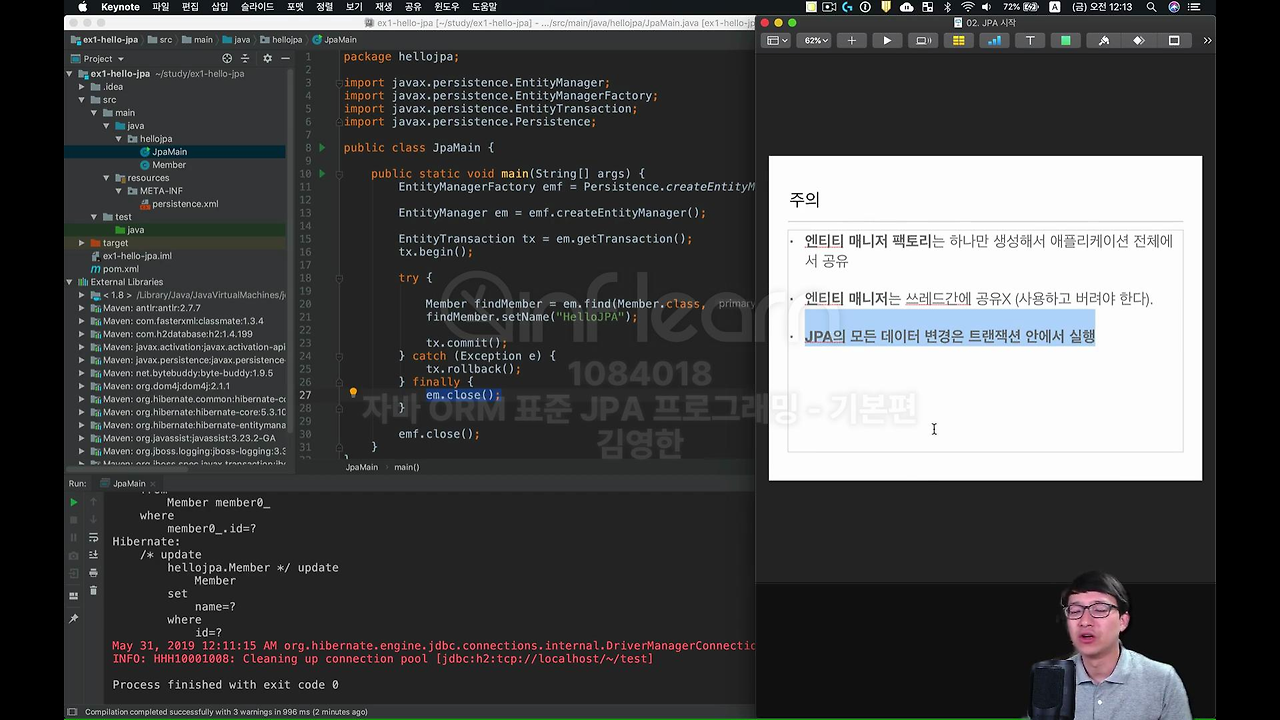
JPA의 모든 데이터 변경은 트랜잭션 안에서 실행하셔야 됩니다.
단순 조회하는 건 트랜잭션 안이 아니더라도 되는데, 그런 게 아닌 이상은 모든 데이터 변경은 트랜잭션 안에서 실행을 해야 돼요. JPA가 아무리 용빼는 재주가 있어도 결국 RDB는 데이터 변경 자체를 트랜잭션 안에서 실행하도록 다 설계가 되어 있어요.
그러니까 여러분이 'DB 트랜잭션 안 해도 데이터베이스 insert, update 되던데요?' 해도, 내부적으로 DB가 트랜잭션이라는 개념을 단 건 쿼리가 올 때마다 내부적으로 다 처리를 해줘서 그래요. 그러니까 트랜잭션을 우리가 안 건다고 해도 DB는 내부적으로 트랜잭션 개념을 가지고 있다고 보시면 돼요.

그래서 이제 가장 단순한 조회.

가장 단순한 조회는 em.find 해서 타입 넣고 pk 넣으면 딱 나와요. 그럼 결과적으로 나온 걸 가지고 화면에 뿌리던가 어떻게 하면 되겠죠.

그런데 이제 막 그런 고민이 있는 거예요. 나이가 18살 이상의 회원을 모두 검색하고 싶다. 아니면 현재 데이터베이스에 있는 모든 회원을 검색하고 싶다. 그러면 어떻게 할 거냐 하면은 이제 거기서 jpql 이라는 것을 여러분이 쓰셔야 합니다. 이거는 간단하게 소개만 드리는 거고 jpql 자체가 굉장히 큰 장으로 되어 있어요.

결국 현업에서의 개발의 고민은 뭐냐면 테이블이 정말 많잖아요. 수 십개부터 수 백개가 될텐데 필요하면 Join도 해야 되고 그렇단 말이에요. 그런걸 어떻게 할 거에요.
그리고 정말 내가 원하는 데이터들을 최적화해서 가져와야 되고 필요하면 약간 통계성 쿼리도 날리고 해야 되는데 이런걸 어떻게 할 거냐는 겁니다.
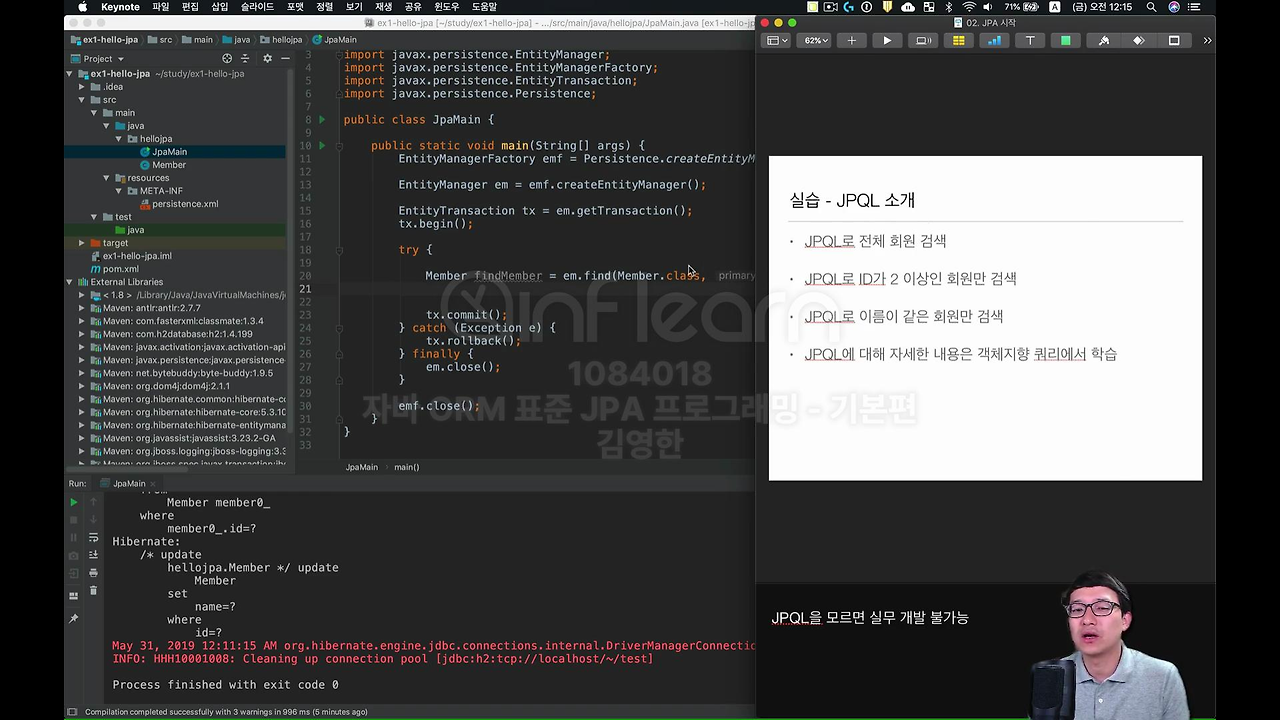
이걸 JPA에서는 JPQL 이라는 걸로 도와줍니다.
실제 rdb를 많이 써보신 분들은 결국 약간 기승전 쿼리거든요. '쿼리를 어떻게 써야하지?' JPA에서도 뭔가 이런 거에 대한 대안책이 다 있습니다. 그게 jpql 인 거구요.
예를 들어서 jpql 로 전체 회원을 조회하고 싶다. 그러면 이렇게 하시면 돼요.
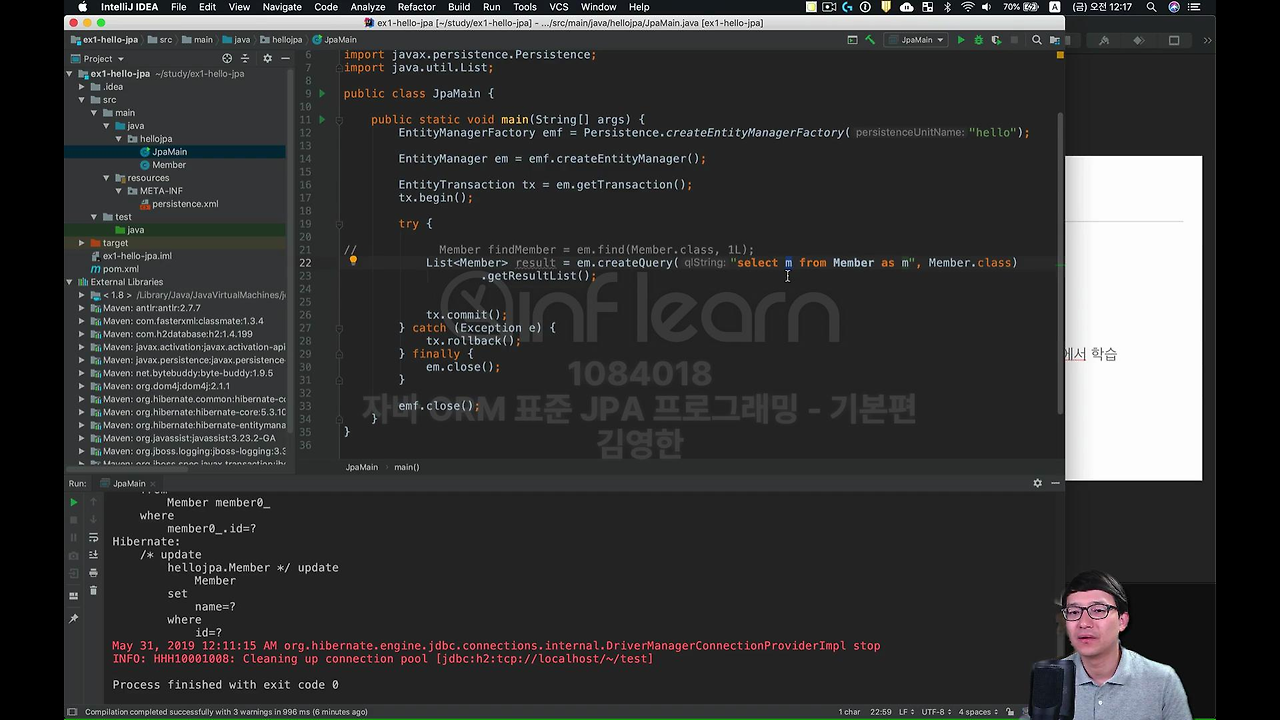
em.createQuery 라는 게 있습니다. 여기에다가 ("select m from Member as m", Member.class)를 넘겨주시면 됩니다. em.createQuery로 query를 칠 수가 있어요.
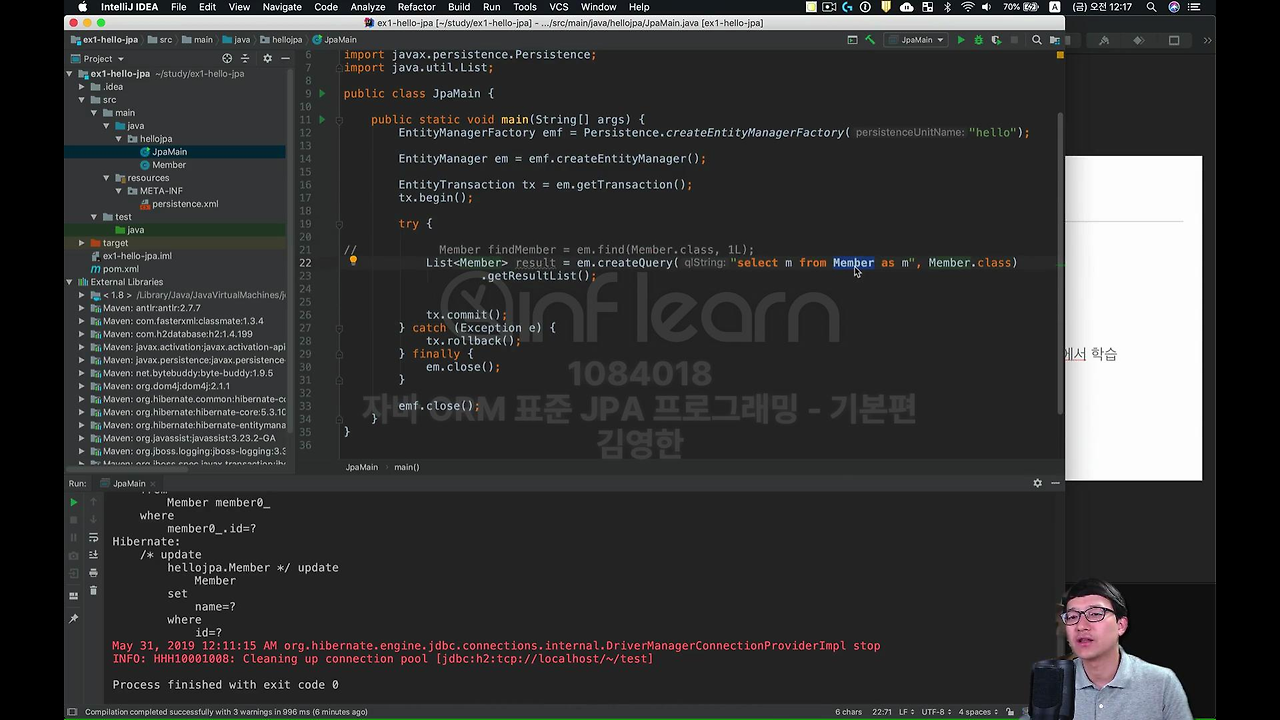
근데 잘 보시면 대상이 달라요. 그러니까 JPA 입장에서는 이 코드를 짤 때 절대 테이블을 대상으로 코드를 짜지 않아요. 이게 뭐냐면 Member 객체를 대상으로 쿼리를 짠다고 보시면 돼요. 'Member 객체를 다 가져와'

보시면 select에 alias m을 넣었잖아요. 그러면 이게 대상이 테이블이 아니고 객체가 대상이 됩니다.

그래서 result 를 뿌리고 iterator 를 돌려서 출력을 해보면,

이름이 잘 출력되고 우리가 생각한 정도의 query가 나가죠.

지금 주석에 있는 건 방금 제가 적은 jpql 이라는 게 적혀 있고요.
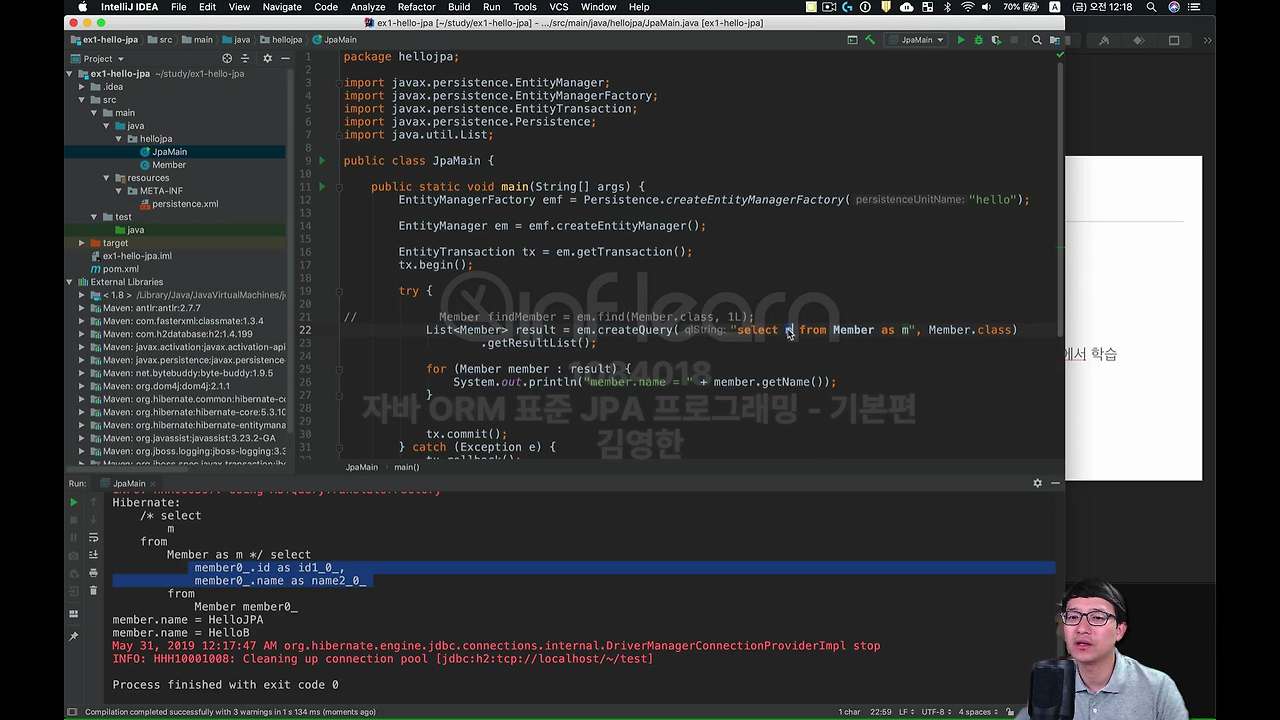
실제 SQL을 잘 보시면 select 하고 필드를 다 나열했어요.
근데 제가 작성한 jpql을 보면 Member 엔티티를 선택한 거라고 보시면 돼요. 약간 이런 SQL과 JPQL 사이의 미묘한 차이들이 조금 있고요. 조금만 배우시면 솔직히 SQL 배우신 분들은 JPQL은 그냥 금방 짜요.
자 JPQL은 엄청난 메리트가 있습니다.
예를 들어서 페이징을 하고 싶어요.
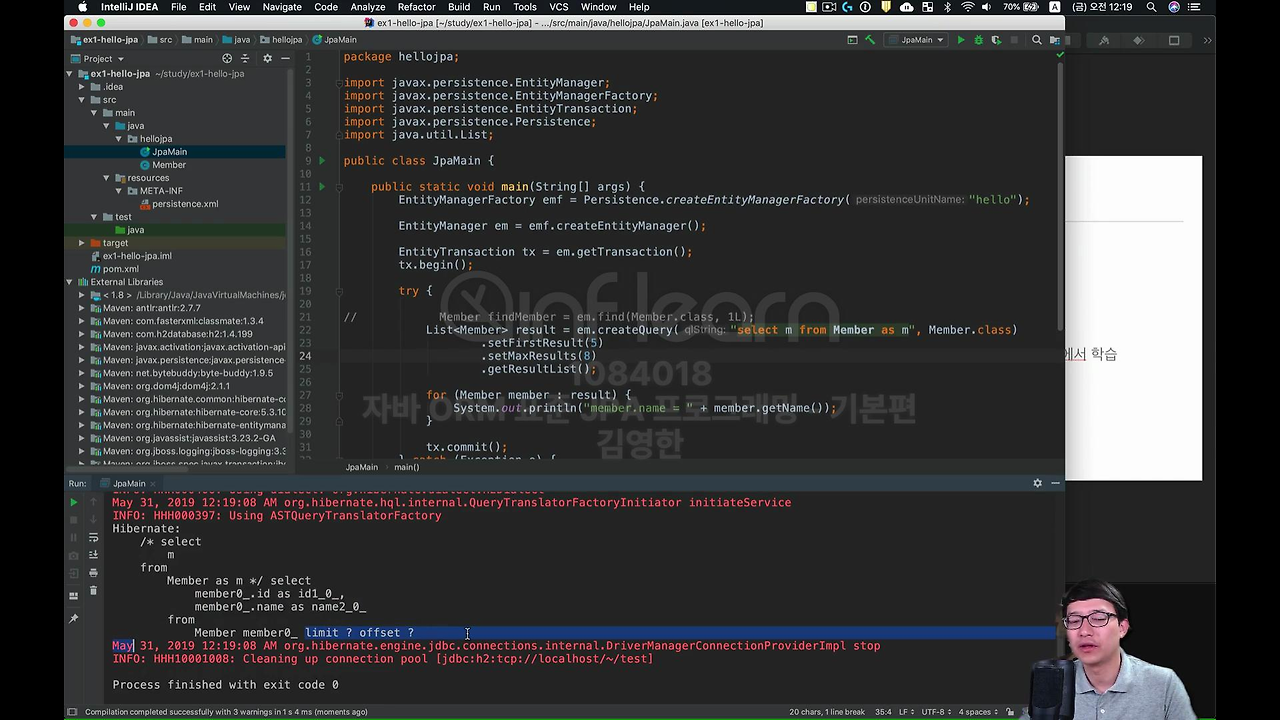
5번부터 8개 가져와! 해서 돌려보면, 지금 결과는 없겠지만 보시면 여기가 Limit ? Offset ? 이게 자동으로 반영이 됩니다.
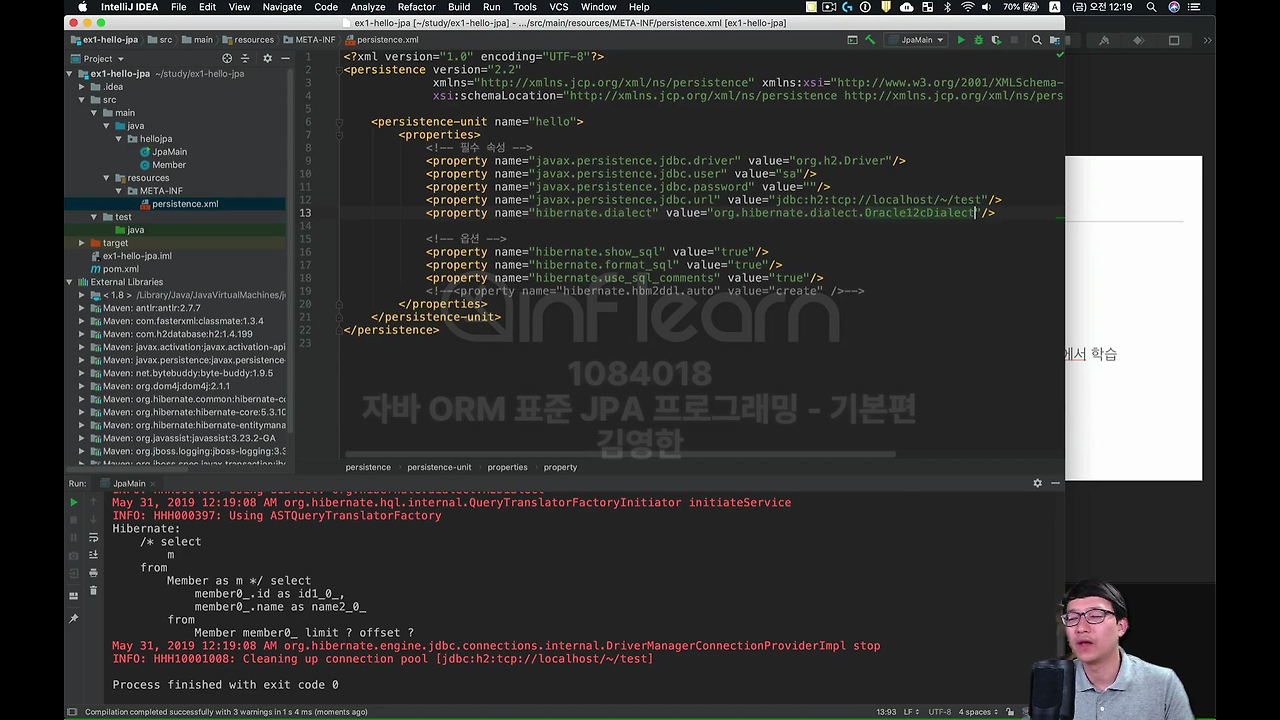
만약에 제가 이걸 Oracle로 바꾸면 앞에 말씀드렸던 방언을 예를 들어서 Oracle로 바꿔서 실행해 볼게요.

쿼리만 바뀐 걸 보는 거예요. 보시면 rownum 보이시죠?
그래서 JPQL이라는 게 객체를 대상으로 하는 객체지향 쿼리라고 보시면 되고, JPQL을 짜놓으면 이게 방언에 맞춰서 여러가지들을 각 DB에 맞게 번역을 해줍니다.

또 여기에다가 만약에 where 해서 m.name 뭐 어쩌고저쩌고 하면 조건에 맞춰서 찾아올 수 있겠죠. 그래서 기본적으로 SQL이 지원하는 대부분의 쿼리는 다 지원이 됩니다.

JPQL에 대해서 좀 부연 설명 드리자면, JPA를 사용하면 결국에는 이 엔티티 객체를 중심으로 개발하게 됩니다.
그런데 이제 문제는 검색 쿼리예요. 이 데이터를 단 건을 가져오는 게 아니라, 검색을 해야 된단 말이에요. 그래서 현업에서 일할 때 Join 엄청 많이 쓰죠. 지금처럼 모든 회원이라던가, 회원 중에 상위 10%의 회원을 조회하라던가 이런 등등 쿼리를 많이 짜게 된단 말이에요. 어쨌든 데이터베이스에 데이터를 최대한 필터링 해서 가져와야 되잖아요. 그러니까 검색 할 때 테이블에서 가져오면 JPA의 객체 중심 개발에 대한 사상이 깨지잖아요. 그래서 테이블이 아닌, 엔티티 객체를 대상으로 쿼리를 짤 수 있는 문법이 들어가 있는 겁니다.

모든 db 데이터를 객체로 변환해서 가져온 다음에 그렇다고 해서 그걸 또 필터링 하거나 이거는 정말 말이 안 되죠.
그래서 결국 뭐냐면 애플리케이션이 필요한 데이터만 db에서 불러오려면 결국에는 검색 조건이 포함된 SQL을 날려야 돼요.
그거를 SQL의 대상으로, 실제 RDB에 있는 실제 물리적인 테이블을 대상으로 쿼리를 날려버리면 DB에 종속적으로 설계가 되어버린단 말이에요.

그래서 그게 아니라 이 entity 객체를 대상으로 쿼리를 할 수 있는 JPQL이라는 게 제공이 되는 겁니다.

그래서 JPA는 SQL을 추상화한 JPQL이라는 객체지향 쿼리 언어를 제공하고요. 그리고 기본적으로 select from, where, group by, having, join 이런 게 다 지원이 됩니다.
아무튼 차이는 뭐냐면 jpql은 엔티티 객체를 대상으로 쿼리를 하는 거구요. SQL은 데이터베이스 테이블을 대상으로 쿼리를 하는게 이제 차이가 있습니다.

그리고 여기서 오는 메리트는 방언을 바꾸거나 해도 그대로 이 jpql 자체를 변경할 필요가 없다는 거죠.
그리고 여기서 이제 나중에 뭐 QueryDSL 이나 뒤에 이제 라이브러리를 설명 드릴 건데 jpql이랑 같이 쓰면, 거의 Java로 다 모든 걸 코딩하면서 정말 신나게 코딩을 짤 수 코딩을 할 수 있죠.
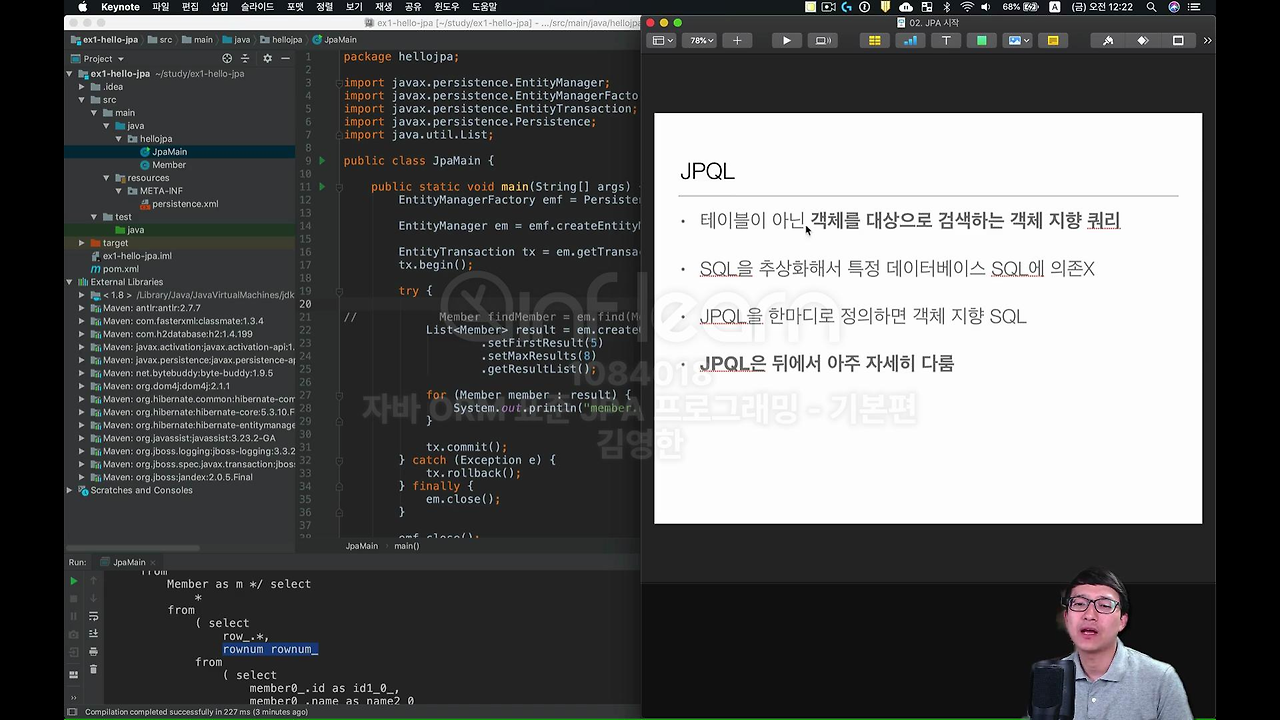
그래서 jpql은 SQL을 추상화해서 특정 데이터베이스 SQL에 의존하지 않습니다. 그러니까 JPQL을 한마디로 정의하면 객체지향 SQL이다. 그리고 이걸 실행을 하면 방언과 합쳐져서 현재 데이터베이스에 맞는 적절한 SQL이 나간다고 이해하시면 됩니다. 그럼 JPQL 배우기 어렵나요? 엄청 쉽습니다.
그래서 이번 시간을 정리해보면,
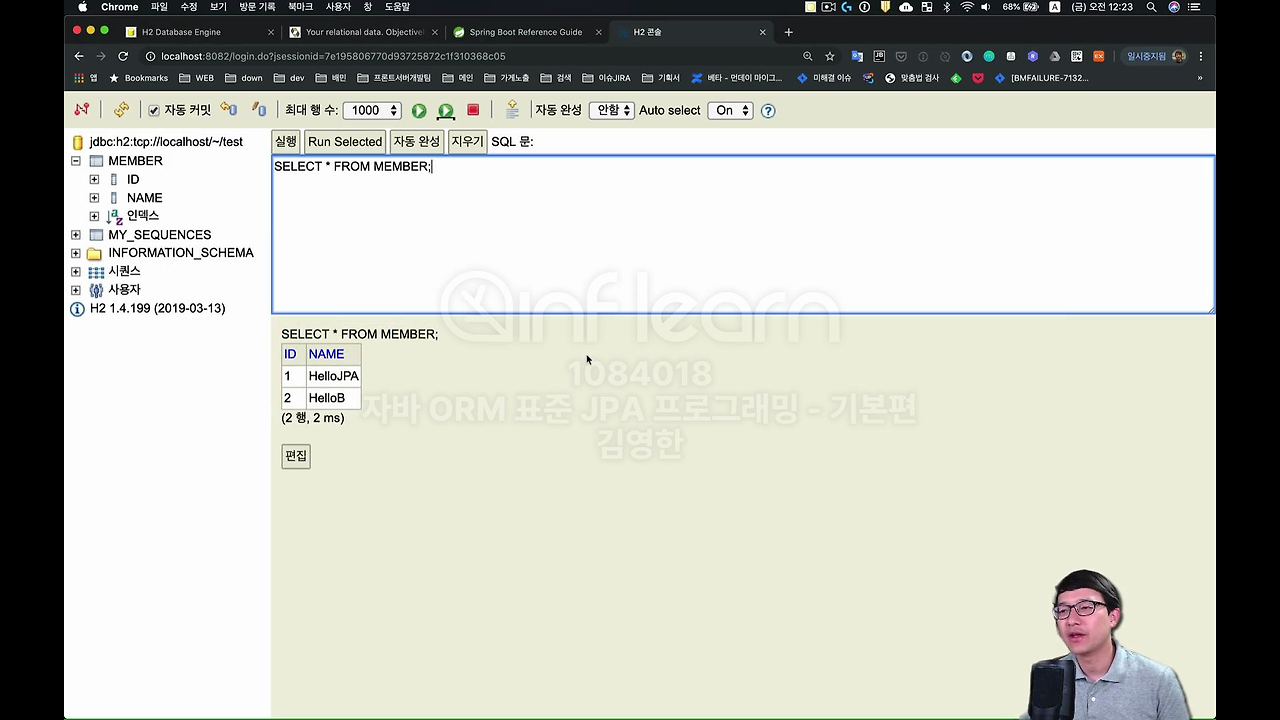
제일 먼저 h2 데이터베이스 띄우고 실행하는 걸 해봤구요.
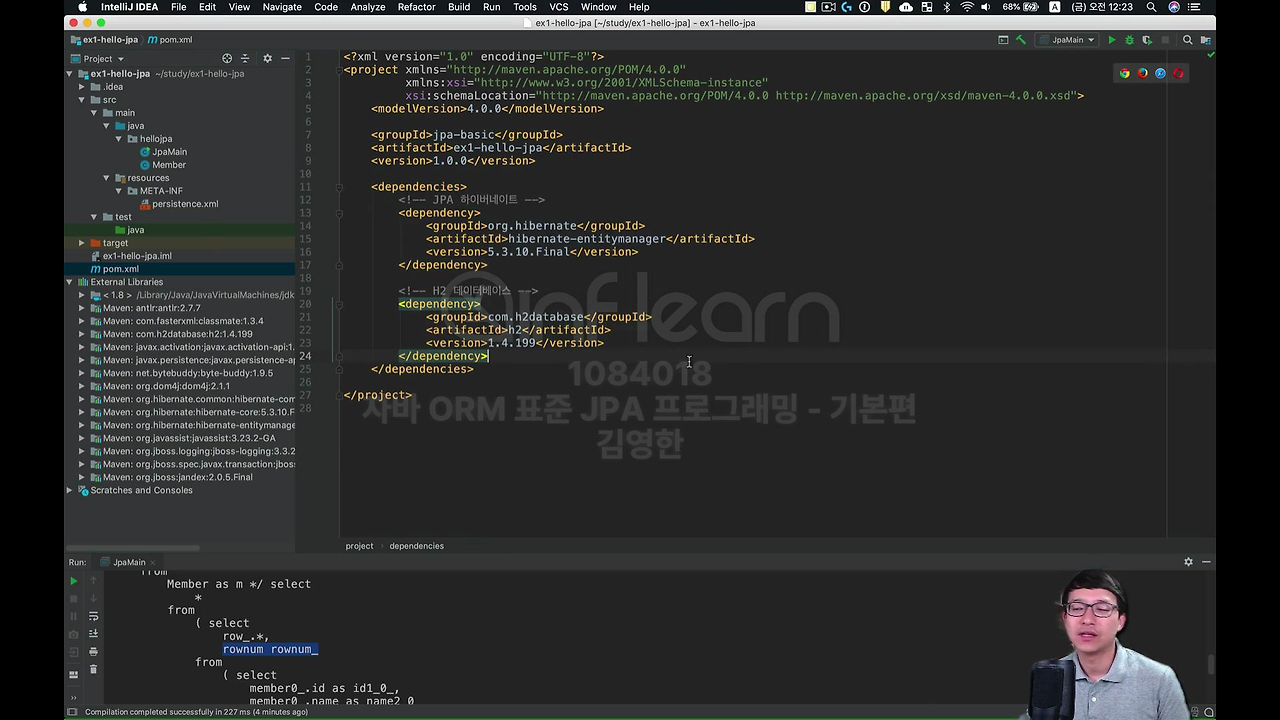
그 다음에 라이브러리를 세팅해서 넣는 거 해봤고,

이 persistence.xml에 대해서 알아봤어요. 이게 있어야 돌아갑니다.
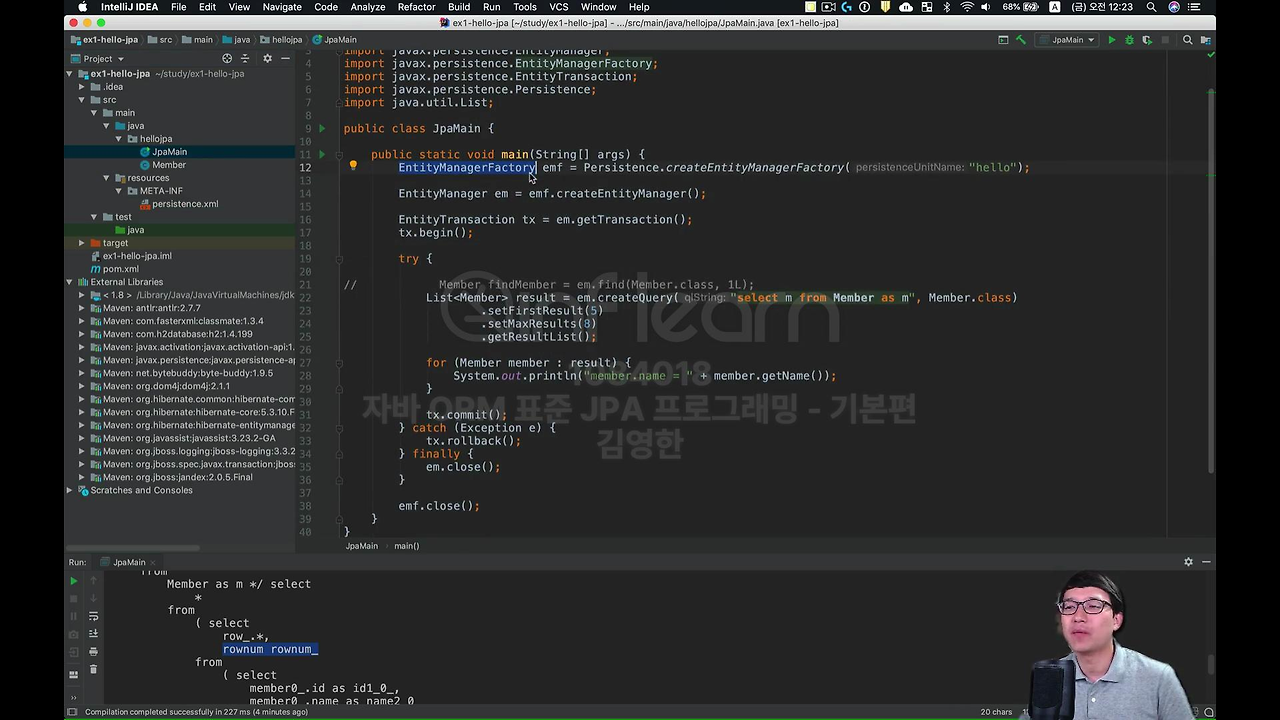
그리고 이제 JPA는 항상 EntityManagerFactory 라는 걸 만들어야 된다. EntityManagerFactory가 데이터베이스 하나씩 묶여서 돌아가는 거구요.
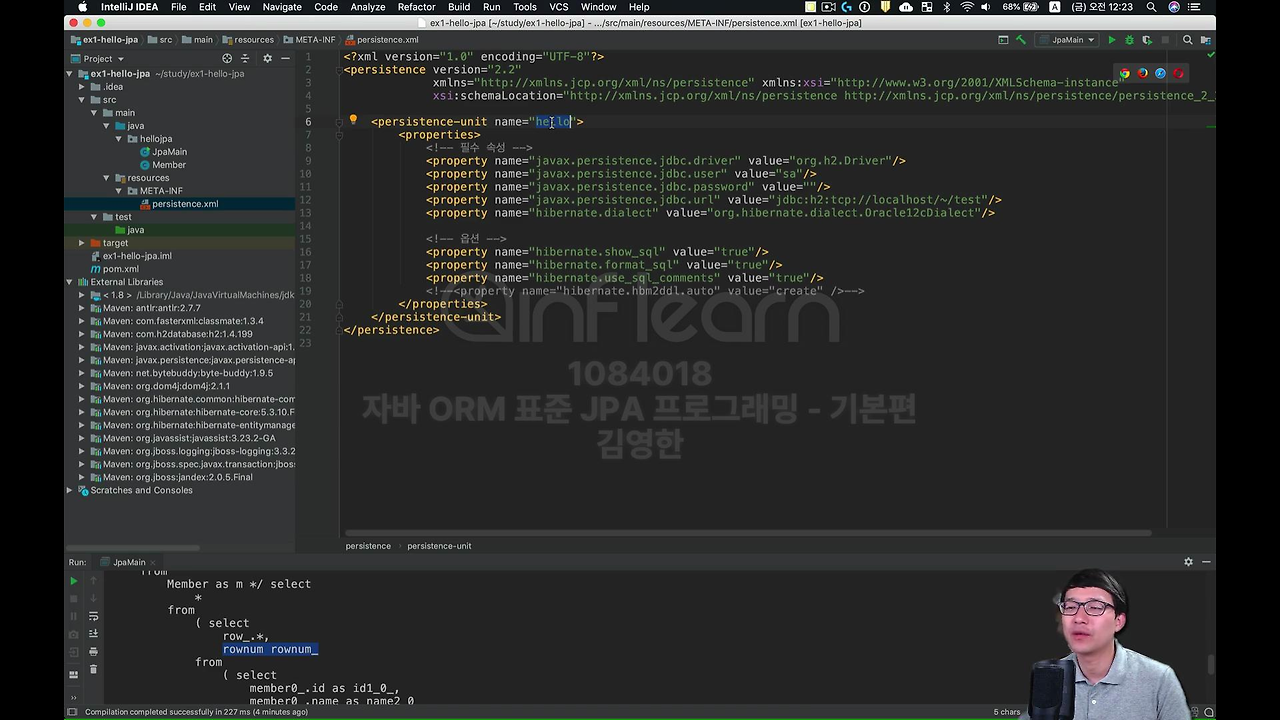
그리고 이 hello 라는 게 설정 파일에서 설정 정보를 읽어와서 만든다.

그리고 JPA는 EntityManagerFactory에서 고객의 요청이 올 때마다, DB 작업을 해야 되면 꼭 Entity Manager를 통해서 작업을 해야 된다.

그리고 JPA의 모든 데이터 변경은 트랜잭션 안에서 일어나야 된다.
그래서 트랜잭션을 시작해서 실제 필요한 로직을 실행을 하고 아까 말씀드렸지만 데이터 변경이 있을 때 단순 데이터 조회 같은 경우에 트랜잭션 선언 안하셔도 동작합니다.
그리고 이제 커밋을 꼭 해줘야 된다. 안 그러면 바꾸면 반영이 안 되는 거죠.
그리고 자원을 다 쓰면 꼭 이건 닫아 줘야 된다. 그래야 내부적으로 데이터베이스 커넥션이 반환 되거나 하겠죠. 복잡한 메커니즘이 있는데 일단 그렇게 생각하시면 돼요.

그리고 웹 어플리케이션 이라고 하면, 와스가 내려갈 때 이 EntityManagerFactory를 닫아 줘야 된다. 그래야 이 커넥션 풀링이나 이런게 내부적으로 다 리소스가 릴리즈가 되는 거죠.
이번 시간에는 여기까지 알아봤고요.
다음 시간에는 본격적으로 JPA에 대해서 실습하면서 알아보겠습니다.
'스프링 > 자바 ORM 표준 JPA 프로그래밍 - 기본편' 카테고리의 다른 글
| 영속성 컨텍스트 2 (0) | 2024.05.26 |
|---|---|
| 영속성 컨텍스트 1 (0) | 2024.05.25 |
| Hello JPA - 프로젝트 생성 (0) | 2024.05.25 |
| JPA 소개 (0) | 2024.05.24 |
| SQL 중심적인 개발의 문제점 (0) | 2024.05.24 |



