
당니의 개발자 스토리
엔티티 설계시 주의점 본문
엔티티 설계시 주의점
이번 시간에는 Entity를 설계할 때의 주의점에 대해서 알아보겠습니다.

먼저 Entity에는 가급적이면 Setter를 사용하지 말자! 앞에서 정말 많이 강조를 해드렸죠. Setter가 모두 열려 있으면 변경 포인트가 너무 많아요. 그래서 특정 Entity 하나가 도대체 어디서 수정된 건지 알 수가 없거든요. 그래서 유지 보수가 어려워집니다.
'어 그럼 Setter를 안 만들면 도대체 어떻게 변경할 수 있나요?'에 대해서는 뒤에 애플리케이션 개발하는 곳에서 제가 실제 비즈니스 메서드를 하나씩 등록하면서 그런 코드들을 가지고 여러분들께 보여드릴게요. 그런 거를 활용하면 충분히 Setter 없이 애플리케이션을 개발할 수가 있습니다.
아 근데 엔티티에는 가급적 Setter를 사용하지 말자고 했는데 우리 예제에서는 Setter를 그냥 열어둘 거예요. 열어둬야 이것저것 편하게 그냥 그때그때 변경할 수 있는 것들이 많으니까요. 그런데 이제 실무에서는 가급적이면 Setter를 열지 말고 사용하는 것을 권장드립니다.
그 다음에

모든 연관관계는 지연로딩으로 설정해야 됩니다. 여러분 이거 엄청 중요합니다. 이거를 들으시면 수많은 장애를 극복하실 수가 있습니다. 이걸 거의 뭐 외우는 수준으로 쓰셔야 됩니다.
자 우선 JPA 좀 공부하신 분들은 이제 즉시로딩과 지연로딩에 대해서 들어보셨을 텐데요.
즉시로딩과 지연로딩의 차이점




먼저 즉시로딩이 뭐냐면,
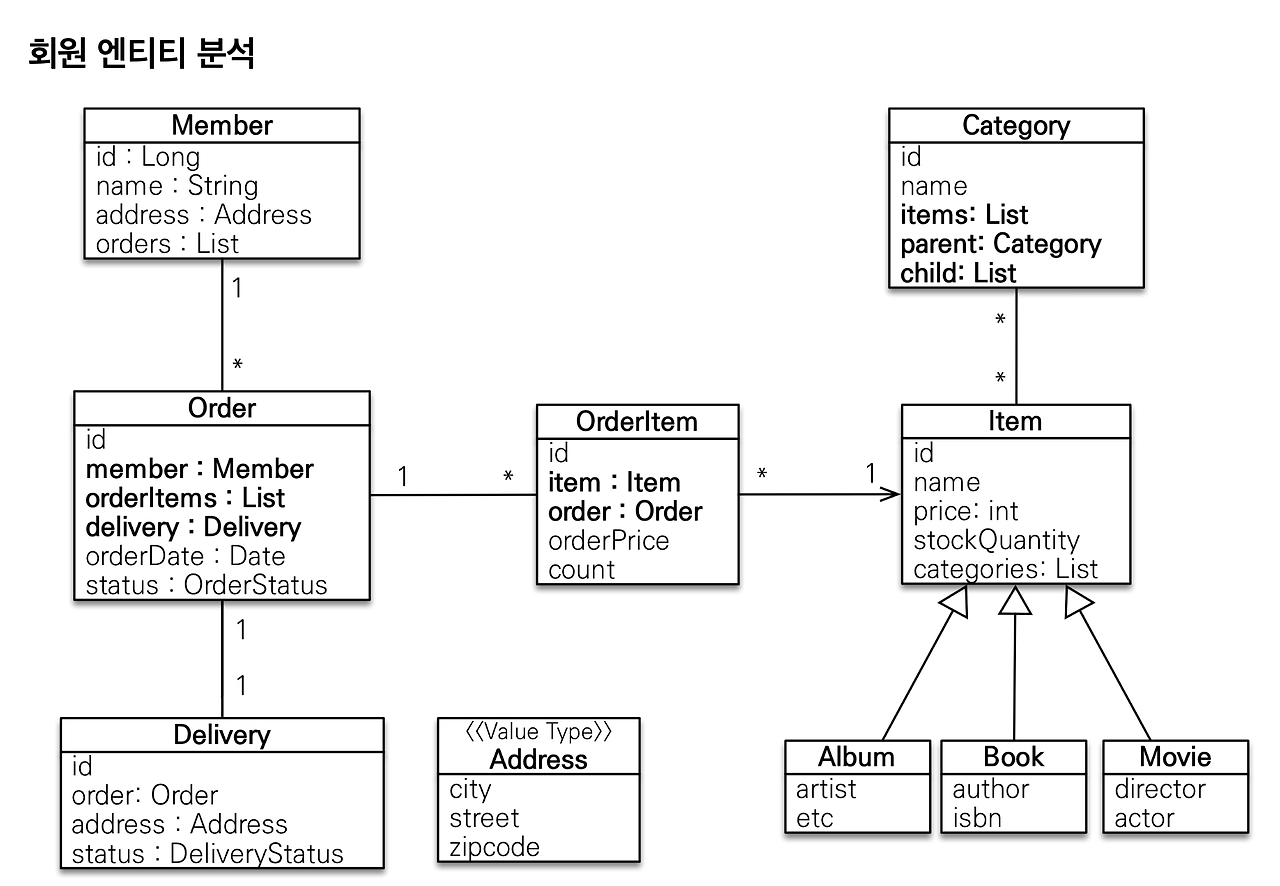
여기서 Member를 조회할 때 연관된 Order를 다 한번에 조회해버리는 거예요. 그러니까 만약에 Order를 조회하면, Order가 필요한 애들(Member, OrderItem, Delivery)을 다 한꺼번에 조회해버리겠다는 겁니다. 그래서 Order를 로딩하는 시점에 다른 애들을 같이 로딩하겠다는 거예요.

즉시로딩은 예측이 어렵고 어떤 SQL이 실행될지 추적하기가 되게 어려워요.

그러니까 최악의 경우에는 Order에 이렇게 다 걸려있으면 하나를 가져오면 연관된 애를 DB에서 다 끌고 와 버리거든요.
제가 이것 때문에 회사에서 한 번씩 JPA 튜닝하러 가서, 도움을 드릴 때가 있는데 이걸로 해놓으신 분들 코드로 보면 처음 한 얘기가 이거예요. 여러분 이거를 LAZY로 다 바꾸세요. 그렇게 해야 튜닝이고 뭐고 할 수 있는 거지, 즉시로딩으로 돼있으면 뭐 하나 잘못 건들면 거기 있는 연관된 데이터를 다 끌고 오는 거예요. 정말 난리 나겠죠.

자 그래서 즉시로딩은 절대로 쓰시면 안됩니다. 그래서 기본적으로 다 LAZY로 세팅을 하시고, 그 다음에 LAZY로 세팅을 해도 문맥에서 내가 필요한 것들을 착착착 찍어서 가져올 수 있거든요. 연관된 엔티티 몇 가지만, 내가 원하는 것만 선택해서. 주로 그걸 fetch join이라 그러는데, fetch join이나 엔티티 그래프라는 기능을 가지고 내가 원하는 그룹을 실시간으로 선택해서 가져올 수 있는 기능이 JPA에 있어요.
그걸로 최적화를 하시면 됩니다. 그리고 사실 JPA Hibernate 에서 이것의 여러 장점에 대해서 많이 밀거든요.
이제 뭐 예를 들어서 궁극적으로 이걸로 최적화도 많이 해주면 어떤 경우가 있냐면,
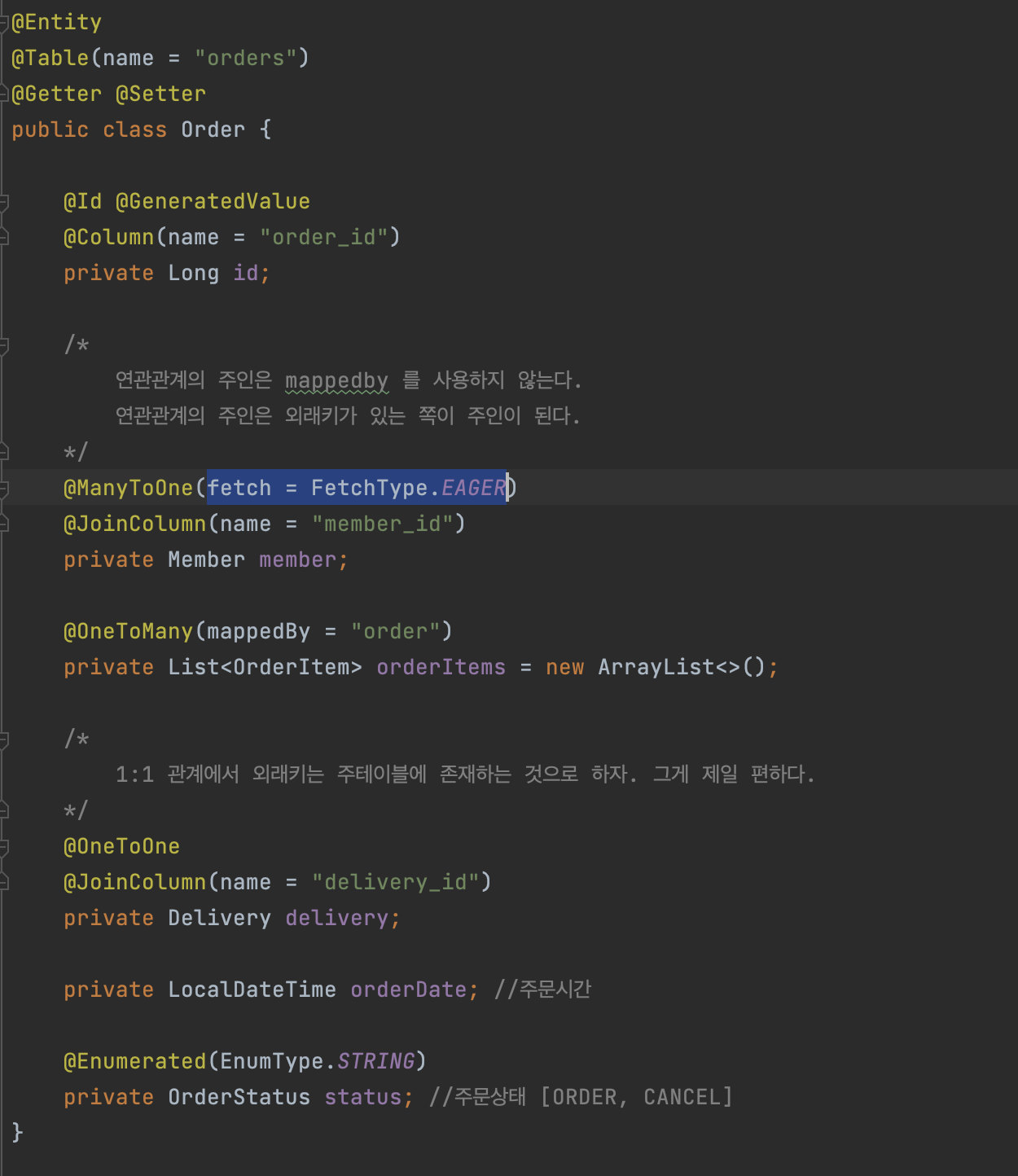
EAGER이 default이긴 한데, 적어봤습니다. 이걸로 Order를 조회할 때 조인을 해가지고, 쿼리 한방에 이 member를 같이 가져요. 그런데 이건 어느 경우냐면,

em.find() 해가지고 1건 조회할 때 Order, 딱 하나 id 찍어가지고 가져올 때는 이렇게 되거든요.

그런데 이제 JPQL이라 그러죠. JPA가 제공하는 쿼리를 가지고 select o from order o; 해가지고 가져와 버리면 문제가 뭐냐면, 이게 SQL로 그대로 번역이 돼요. EAGER 이런 거 다 무시하고 그냥 일단 얘가 그냥 select * from order 이런 식으로 번역이 된단 말이에요.
그러면 select * from order로 가지고 오면 일단 Order가 한 100개가 조회가 됐어요. 100개가 있어서 100개를 딱 가져왔는데 '헉. 큰일났어! Member가 EAGER로 돼있어!' 그러면 100개가 100번,

이거를 가지고 위해서 단방 쿼리가 100개 날라갑니다. 그게 이제 n + 1 문제라고 그러죠.
왜 n + 1 이냐면 1 + n 이라고 봐야 될 것 같은데,

첫 번째 날린 쿼리(1)가 가지고 온 결과가 100개면,

이걸 100으로 취합하시면 돼요.

그래서 이만큼 처음에 Order 날리는 쿼리가

한번 날라가서 그 결과가 100개인데 그만큼 이 member를 가지고 오기 위해서 단방 쿼리가 날라갑니다.
일단은 EAGER의 뜻은 join 해서 한 번에 가져온다는 게 아니라, 일단 어떻게든 Order를 내가 조회하는 시점에 member를 꼭 같이 조회하겠다는 거거든요. 아무튼 그래서 난리가 납니다.

JPQL을 실행할 때 N+1 문제가 자주 발생이 돼요. 그래서 일단은 여러분 다 지연로딩으로 바꾸셔야 됩니다.
자 그 다음 지원로딩으로 다 바꿔 놓으면 일단 Order를 조회할 때 Order만 가져오거든요. 근데 이럴 때 있잖아요. 이 로직에서는 Order를 조회할 때 member도 같이 필요해! 하면서 단방 쿼리를 같이 끌고 오고 싶어! 라고 하면 fetch join 이라는 걸 쓰시면 됩니다. 기본편에서 자세히 설명 드리니까요. 그리고 참고로 이 강의 뒷부분에서 API 최적화 하는 데서도 설명을 드립니다. 그것도 최근에 나온 엔티티 그래프 기능을 쓰시면 됩니다.

그런데 여러분 이걸 엄청 조심해야 돼요. JPA 맵핑할 때, OneToOne, ManyToOne 이런 거 쓰시잖아요. 그런데 가보시면,

기본 fetch가 이겁니다. 그런데 '어? 이상하다' 라고 하시는 분들이 있을 거예요.
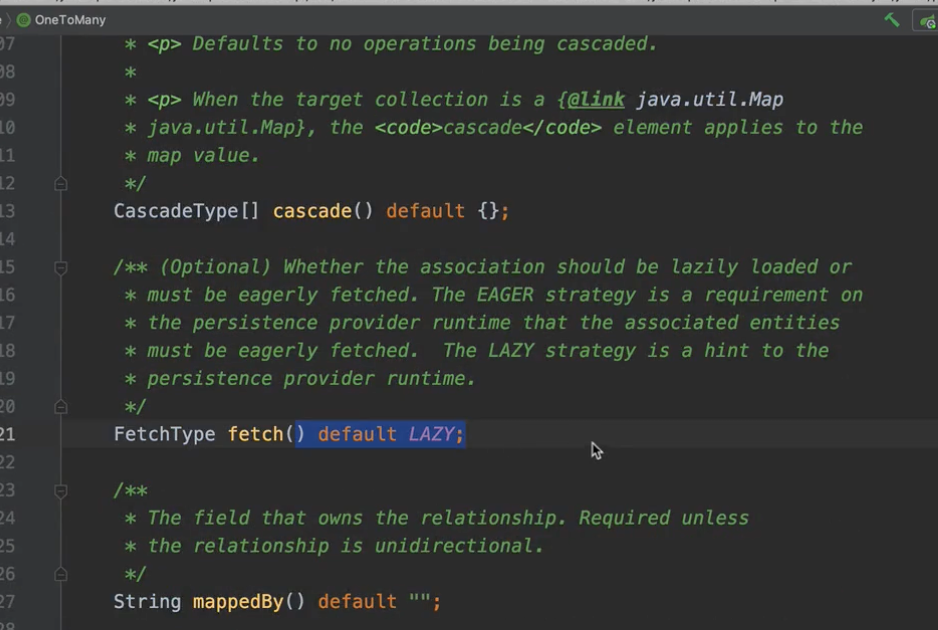
왜냐면 OneToMany는 기본이 LAZY란 말이에요. 두 개가 달라요. 다 LAZY 였으면 우리가 할 게 없을 텐데, 이게 지금 OneToOne, ManyToOne처럼 하나를 찌르는 애는 기본 fetch 전략 자체가 EAGER로 되어 있단 말이에요.

근데 얘는 기본 fetch 전략이 LAZY예요. 어느 정도 얼핏보면 합리적인 것 같아요. 왜냐면 하나를 가져오는 건 뭐 그렇게 무겁지 않은 작업 같으니까 EAGER가 디폴트고, 이제 Many로 가는 거는 컬렉션을 가져다 놓으면 무거우니까 LAZY로 디폴트가 되어있다고 생각하실 수 있는데 아까 말씀드린 JPQL에서 Order 100개가 조회가 되면 이게 100번 쿼리가 나가기 때문에 완전 망하게 됩니다.
자 그래서 이제 결론은 뭐냐면,
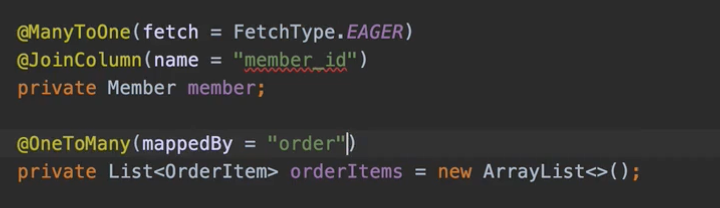
OneToMany, ManyToMany 같은 xxToMany 시리즈들은 기본이 LAZY이기 때문에 그냥 이거를 놔두시면 돼요.

그런데 OneToOne, ManyToOne은 여러분 전부 다 코드 찾으셔가지고 LAZY로 다 바꿔줘야 돼요.
안 그러면 진짜 난리납니다. 뭐 하나 찝어 왔더니 막 연관된 애들, 이상한 쿼리들이 막 다 나가는 거예요. 그래서 막 실제 select를 해보면 난리가 나는 거죠.
자 그래서 이제 실무에서는 EAGER를 쓰시면 안 됩니다.
그러면 이제 @OneToOne, @ManyToOne을 다 찾아야겠죠. cmd + shift + F 해서,

이렇게 다 찾아서 바꿔줍시다.
그 다음에 option + enter 하셔서,

static import로 하면 더 예쁘겠죠.

@OneToOne도 똑같이 바꿔줍니다.
자 다시, 모든 건 지연로딩으로 다 잡으셔야 됩니다. 나중에 '왜 EAGER로 잡으셨어요?' 라고 물어보면 이제 이런 대답들이 나오거든요. 그 LAZY 로딩이 트랜잭션 밖에서 안되는 이슈들이 있거든요. LAZY 로딩 exception이 나서 EAGER로 바꿨다. 라고 대답하시는데 그것도 다 대안이 있어요. 뭐 트랜잭션을 좀 빨리 가져온다거나, 아니면 상황에 따라서는 'Open Session In View(OSIV)'라고 그런 방식을 쓰거나 해서 다 해결책이 있습니다.
궁극적인 해결책은 거의 fetch join 으로 해결이 되는데 다 해결이 됩니다.

그 다음에 이제 이거는 주로 질문이 많이 오거든요.
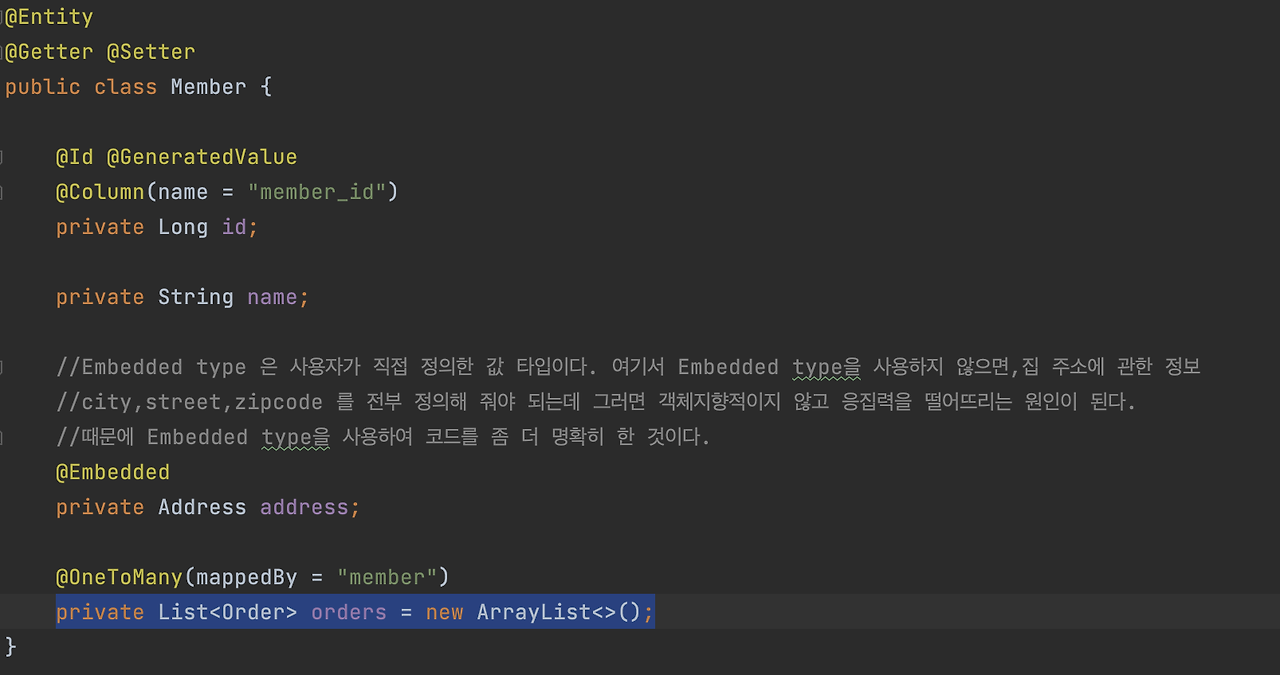
Member에 보면 이 부분을 보고 고민을 하는게 어떻게 보면 당연한 건데,
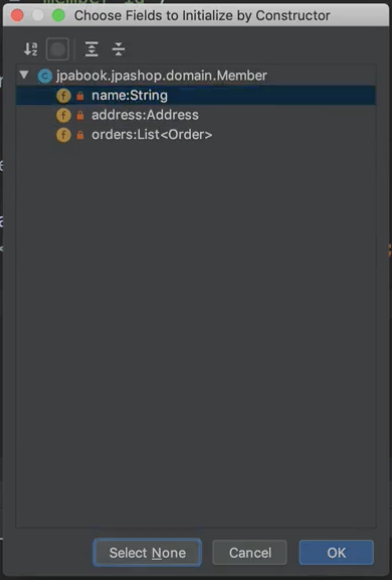
Select None을 해서,
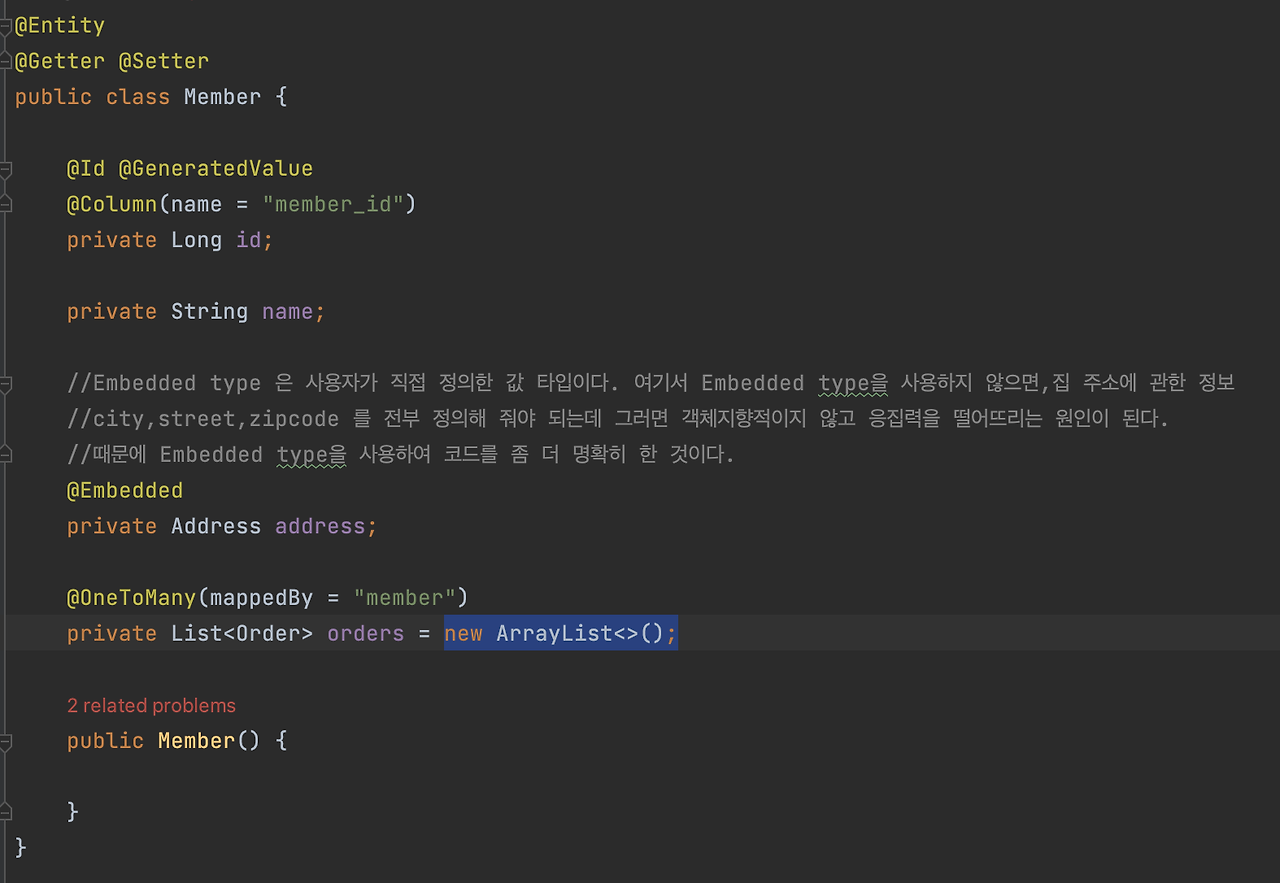
이렇게 있을 때 지금처럼 조회를 할 지,
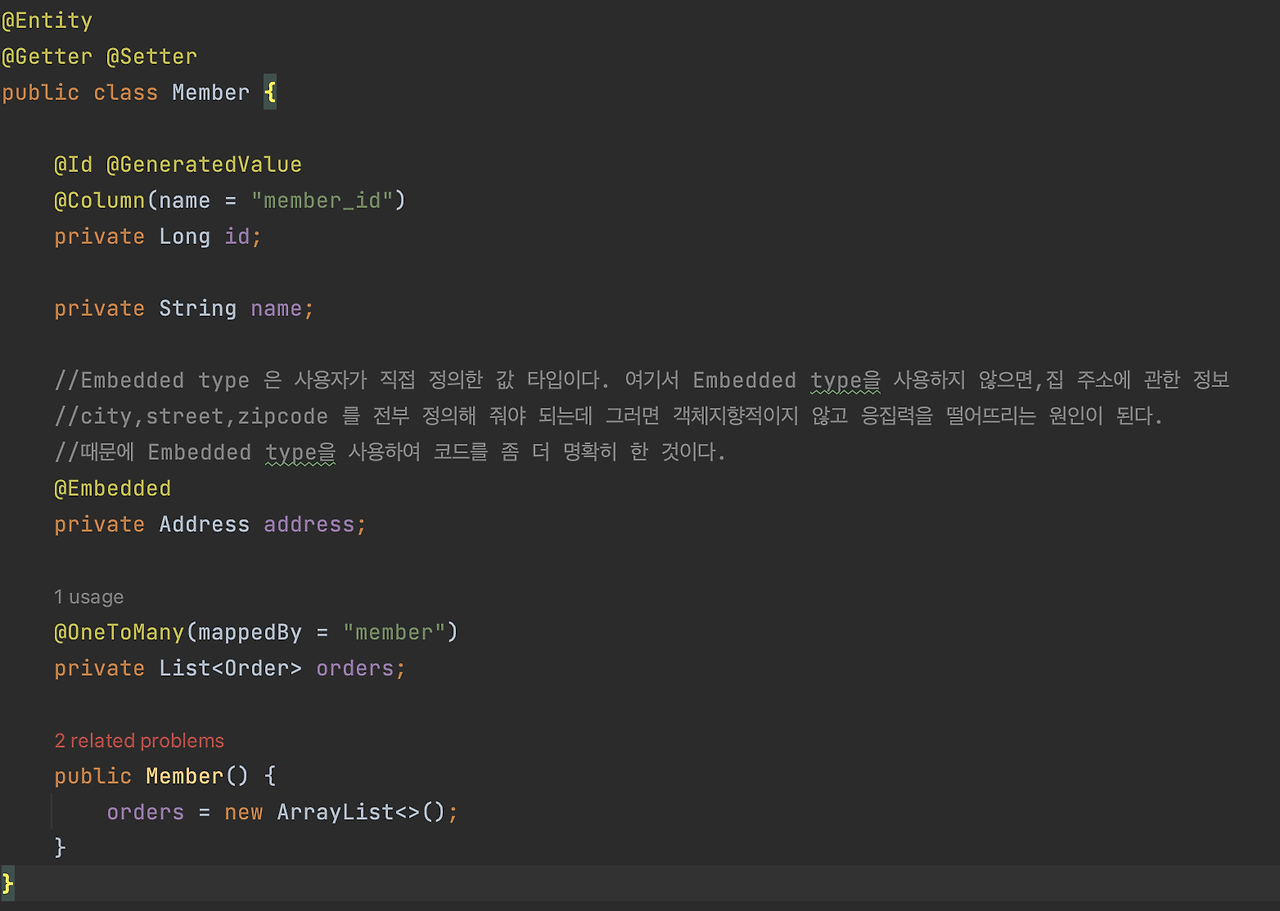
아니면 이런 식으로 초기화를 해도 되잖아요. 아니면 또 다르게 해서 주입을 할지 이런 고민들이 있을텐데 이거는 Best Practice가 있어요. 예전에 Hibernate 가이드에 Best Practice가 나왔는데, 거기 보면
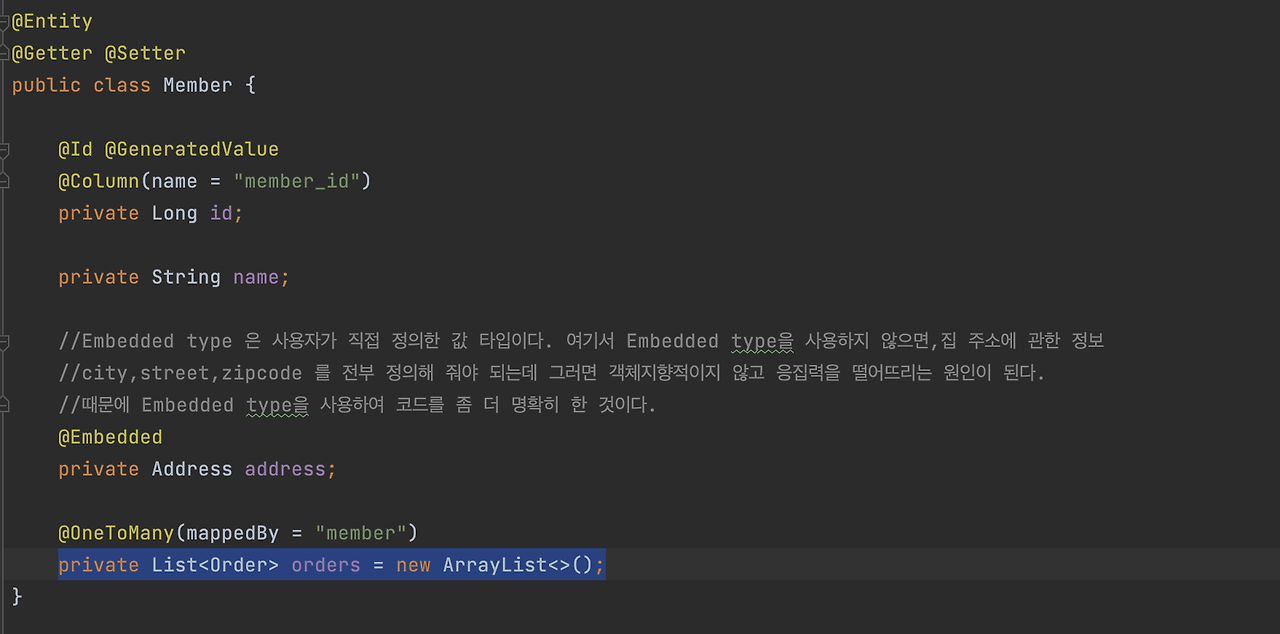
이게 여러분 Best Practice 입니다. 이게 뭐 여러가지 이유가 있지만, 이렇게 하면 우선은 초기화에 대해서 고민을 안해도 되죠.
그러니까 NullPointException을 날릴 일이 없죠. 잘못해서 없는데 막 체크해야 되잖아요. 이거 하나 넣는다고 메모리 얼마 먹지도 않아요.

그래서 초기화를 필드에서 바로 하는 게 안전하고, Null 문제에서 안전해지죠. 그런데 그것보다는 사실은 문제가 있어요. Hibernate가 엔티티를 persist 하는 순간 컬렉션을 한번 감싸버려요. 뭐 감싸거나 하여튼 뭔가 지가 안에서 지지고 볶아요. 그래가지고 Hibernate가 제공하는 내장 컬렉션으로 변경이 돼버려요.
자 무슨 말이냐,

첫 줄에 보시면, Member 객체를 생성했단 말이에요. 그 다음에 System.out.println(member.getOrders().getClass());으로 찍어보면, ArrayList가 나와요.
문제는 뭐냐,

얘를 persist로 영속한단 말이에요. JPA 입장에서 이건 이제 db에 저장하겠다고 선언하는 거죠.
그러면 어떻게 되냐면,

다음부터 얘는 영속성 컨텐츠를 관리를 해야 되거든요. 이 orders 컬렉션을.
그 다음에 다시 System.out.println(member.getOrders().getClass());으로 찍어보시면,

이상한 애로 바뀌어 있어요.
Hibernate가 기존 거를 들고 감싸버리는 거예요. 왜냐면 Hibernate가 이 컬렉션이 변경된 걸 추적해야 되기 때문에, Hibernate가 추적할 수 있는 본인의 PersistentBag이나 뭐 타입에 따라 다른데 하여튼 얘를 바꿔 버려요. 문제가 뭐냐?
Hibernate가 기껏 이걸로 바꿔놨는데 누군가 여기다 또 set 해가지고 이 컬렉션을 바꿔버리면 어떻게 되겠어요? Hibernate가 원하는 메커니즘이 안 돌아가는 거예요.
그래서 어떻게 해야 되냐면,
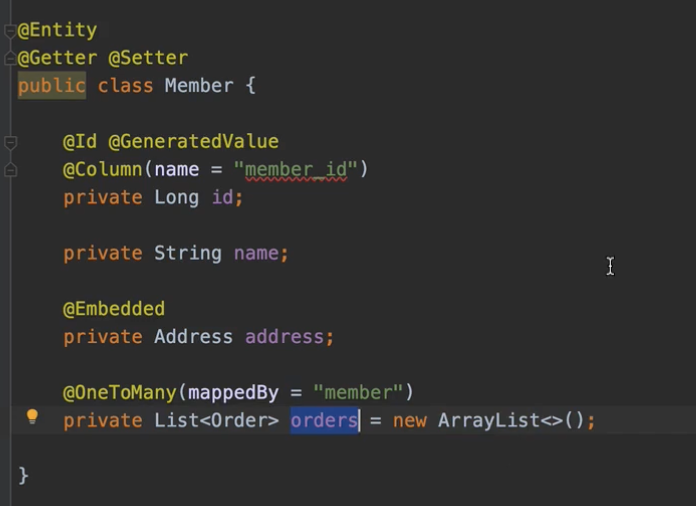
이 컬렉션을 그냥 여러분 이렇게 딱 생성하고 이 컬렉션을 가급적이면 밖으로 꺼내지도 말고, 뭐 꺼내면 수정을 안 하면 괜찮아요. 이 컬렉션을 가급적이면 변경하시면 안 돼요. 그냥 딱 처음 객체 생성할 때 딱 해두시고, 절대로 이 컬렉션 자체를 바꾸지 마세요. 있는 거를 그대로 써버리세요. 그게 제일 안전합니다. 어떤 메서드에서 체크해서 뭐 어쩌고 저쩌고 이런 로직을 넣는 것도 힘들고 무엇보다도 Hibernate가 관리하는 컬렉션으로 바꼈기 때문에 이 컬렉션을 함부로 바꾸시면 Hibernate가 원하는 메커니즘 대로 동작을 안 할 수 있습니다.

그래서 정리하면 컬렉션을 필드에서 바로 초기화 하는 것이 가장 좋습니다.
그 다음에 테이블이랑 컬럼명을 생성하는 전략이 있어요.


이 링크 타고 가보시면 되는데, 한번 보여드릴게요.
Member로 해볼게요. @Table이라고 주면,

테이블 명을 Member를 그냥 user라고 바꿀 수도 있어요. 그럼 default로 아무것도 안 하면 어떻게 돼요? 이때 어떻게 할 건지에 전략이 있습니다.

이게 버전마다 다른데 Spring Boot를 쓰시면 Spring Boot가 SpringPhysicalNamingStrategy 라는 애를 써요.
SpringPhysicalNamingStrategy는 뭐냐면,

저도 이 방식을 굉장히 좋아하는데 얘는 camelCase를 underscore로 바꿉니다. 예를 들어서 memberPoint라는 애가 있으면 member_point로 바꿔요. 그 다음에 .(점)은 Underscore로 바꾸고 대문자를 다 소문자로 바꿉니다.

자 그래서 여기 orderDate 같은 경우에는 어떻게 바뀌냐면, 얘가 order_date로 바껴요.
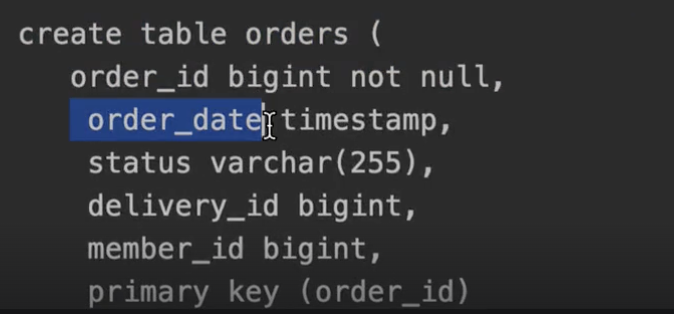
실제로 바껴있는 걸 보실 수 있습니다. 기본 전략이 자바의 camel 케이스를 다 underscore 스타일로 바꾸고 다 소문자로 바꿔버린다는 거예요. DBA분들은 전통적인 관례상 underscore를 정말 많이 쓰거든요. 이런 것도 맞춰줘야 된단 말이에요. 그리고 이걸 왜 또 말씀드리면 과거 Hibernate나 JPA에서는 테이블의 컬럼명도 orderDate면 orderDate라고 똑같이 그대로 만들어졌어요. 그랬는데 이제 Default가 바뀐거에요.
그래서 Spring Boot를 쓰시면,

SpringPhysicalNamingStrategy가 기본으로 되어있습니다.
참고하시고 링크에 있는 메뉴얼들을 따라가보시면 됩니다. 그래서 '왜 이렇게, 이런 이름으로 생성이 되지?' 하면 이것 때문에 된다고 보시면 됩니다.

혹시 바꾸고 싶으시면 이 설정을 spring.jpa.hibernate.naming.physical-strategy를 클래스를 구현하셔서 바꿔치기 하시면 됩니다.

그리고 스프링 부트는 기본으로 이렇게 세팅이 되어 있구요. 이제 논리명 물리명이 있는데, 이거는 뭐 궁금하신 분들 한번 찾아서 보세요.
자 그리고 뭐 이정도 하고, 그러니까 기본 전략을 그냥 따라가시면 됩니다.
근데 막 회사에서 아 우리 회사에만의 기본 전략이 있다고 한단 말이에요. 뭔가 그냥 전사적으로 가지고 있는 전략이 있어요. 예를 들어서 무조건 앞에 xx를 붙인다. 라고 하면 SpringPhysicalNamingStrategy를 참고하셔가지고 이 코드를 바꾸시면 전사 로직으로 다 적용하실 수가 있습니다.

참고로 더 덧붙이자면 이게 논리명이 있고 물리명이 있거든요. 논리명이 뭐냐면 이제 명시적으로 테이블 컬럼명을 지정하지 않으면 어떻게 생성해줄지의 전략이구요. 물리명은 모든 논리명에 다 적용이 됩니다.
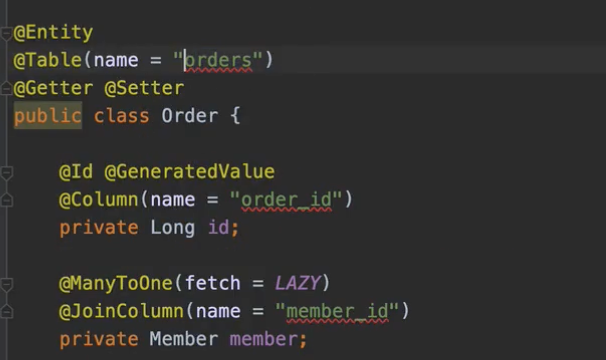
여러분이 이렇게 직접 적으신 거에도 JPA에서는 지금 orders 라고 적었지만, 앞에 xx_orders 라고 전사 표준어가 앞에 xx를 무조건 붙여야 돼! 라고 한다거나, 아니면 모든 테이블 명에는 프로젝트 이름을 적어야 돼! 라고 해서 jpashop_orders 라고 한다거나 하면, 모든 테이블마다 직접 해주기는 좀 그러니까 naming.physical-strategy를 해주시면 됩니다.
물리명에다가 해주시면 다 그렇게 바뀌게 됩니다. 자 그래서 논리명은 테이블에 컬럼명을 적지 않았을 때 이름을 뭘로 할 거냐는 거고, 물리명은 테이블의 컬럼명이 적혀 있든, 적혀 있지않든 일단 어쨌든 모든 곳에 다 적용하는 rule이라고 보시면 될 것 같아요.
이렇게까지 설명 드렸고, Order에 가보시면

CascadeType 이라고 있는데 이걸 설명드릴게요.
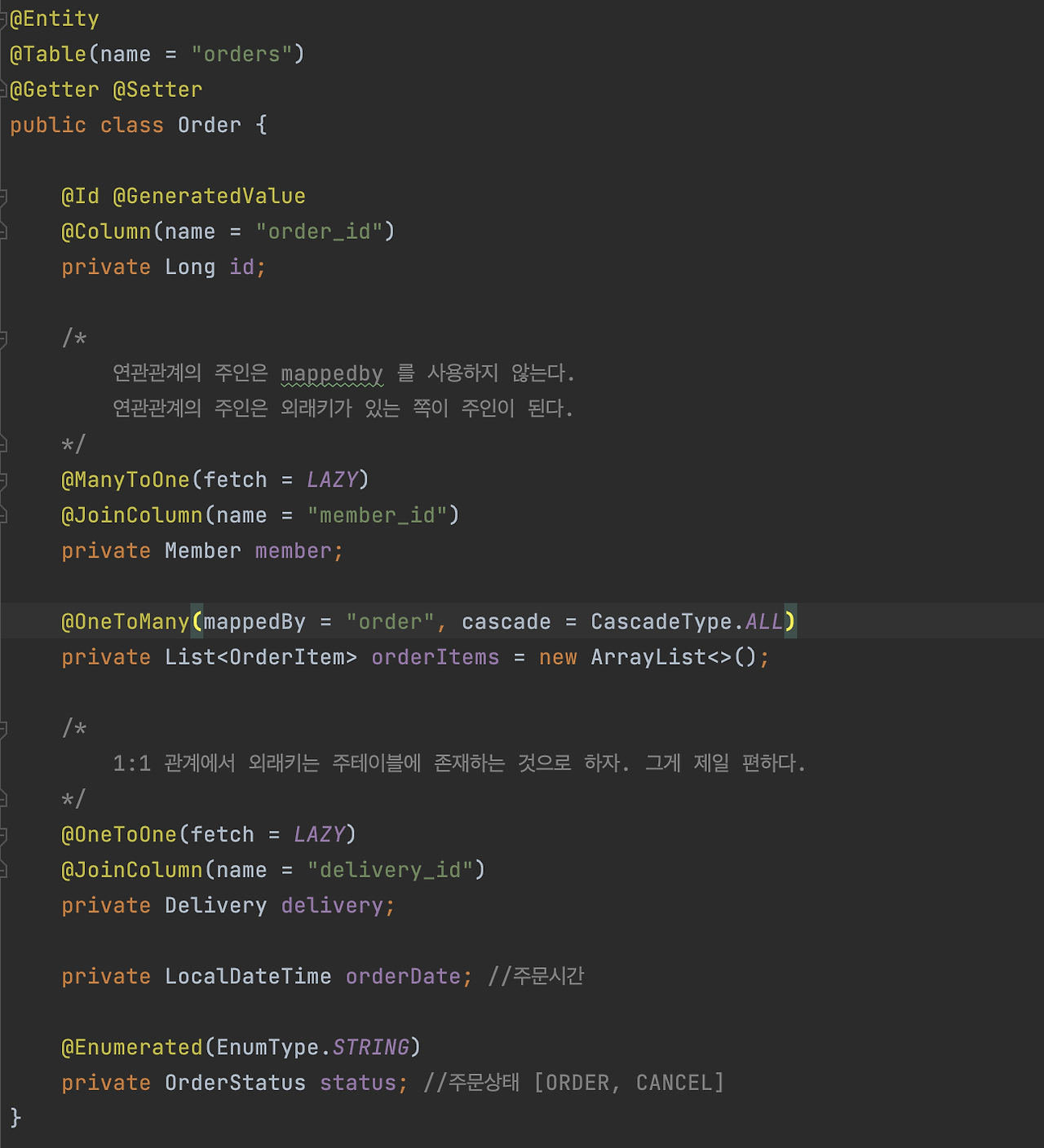
여기 orderItems에 CascadeType.ALL 라는 옵션을 썼어요. orderItems에 데이터를 넣어두고 Order를 저장하면 orderItems도 같이 저장이 됩니다. 원래는 Order 저장하고 orderItem을 쭉쭉 저장을 한 다음 이렇게 막 해야 되거든요. 그러니까 JPA에 orderItem를 3개면 3개를 다 저장을 하고 컬렉션에 넣은 다음에 또 JPA에다가 Order를 persist 해서 저장을 해줘야 돼요.
코드로 말씀드리면,

예를 들어서 orderItemA, B, C를 JPA persist 해서 이렇게 해줘야 되거든요.
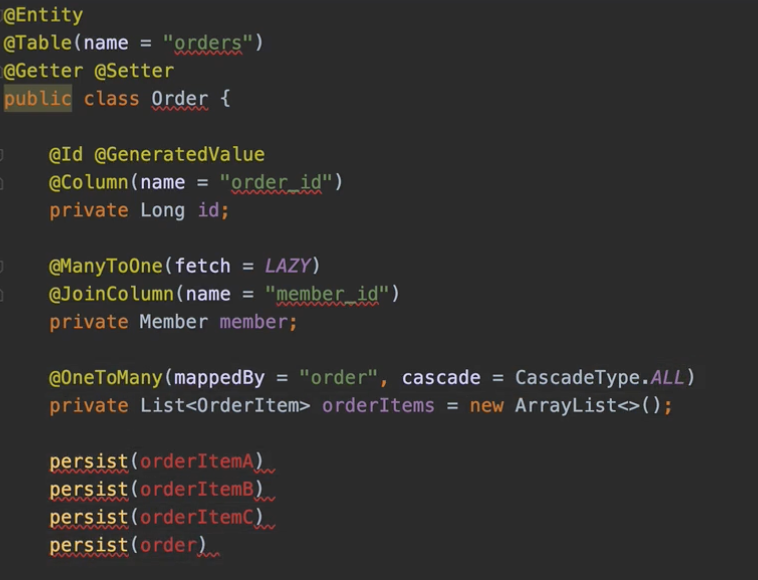
그 다음에 persist 해서 Order를 이렇게 넣어줘야 돼요. 엔티티당 각각 무조건 persist를 호출해야 되거든요.
그런데 cascade를 두시면 persist(order)만 해주시면,

위의 코드는 지워도 됩니다. 그러니까 cascade를 하고 안하고 차이가 있죠. order를 persist 하면 cascade는 persist를 전파하거든요. 그래서 이 order item collection에 있는 A, B, C를 collection에 담아놨으면 얘네를 다 persist를 같이 해줍니다. CascadeType을 All로 해놨기 때문에 delete할 때도 같이 다 지워버립니다.

delivery로 이렇게 되어있네요. 이게 무슨 말이냐면, 지금 delivery 값만, 객체만 세팅해놓으면 Order 저장할 때 delivery 엔티티도 같이 persist 해줍니다. 원래대로라면 delivery도 직접 persist를 해주고, Order도 직접 persist를 각각 해줘야 돼요.
모든 엔티티는 persist를 기본적으로 저장하고 싶으면 각자 해줘야 되는데 여기 delivery 값만 세팅을 해놓고, Order만 persist 해줘도 persist까지 같이 persist 호출이 됩니다.
그 다음에 이제 마지막으로 Order에 보시면,

연관관계 편의 메서드 라는 게 있어요. 이거는 뭐냐면 여러분 양방향 연관관계 세팅하려면, Order랑 Member가 있으면,

자 Member가 주문을 하면 여기 Order의 리스트에 넣어줘야 되겠죠. 왜냐면 양방향이니까 뭐 연관관계 주인 이런걸 다 떠나서 객체는 어쨌든 값을 양쪽에 다 넣어 줘야 되잖아요. 그래야 member.getOrder()에서 주문한 걸 찾을 수 있고 order.getMember() 해서 양방향이니까 객체적으로 왔다갔다 할 수 있겠죠? 그러면 양쪽에 값을 세팅해주는 게 제일 좋거든요.
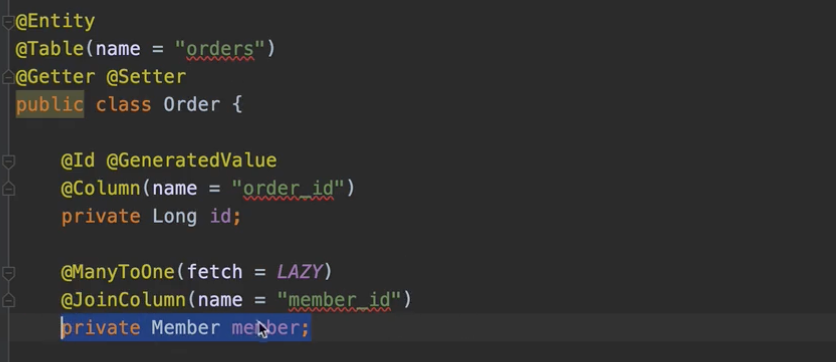
물론 얘가 연관관계의 주인이니까 db에 저장하는건 여기 Order.member에만 있으면 되는데, 그래도 로직을 태울 때 왔다갔다 하려면 이게 있어야 된다고요.
자 이제 코드로 직접 쳐보겠습니다. 저는 연관관계 편의 메서드라고 하는데 줄여서 연관관계 메서드라고 할게요.

자 member를 세팅할 때 this.member에 member를 넣겠죠. Order 입장에서 Order에 코드를 넣을 때 반대로 양방향을 넣어야 돼요.
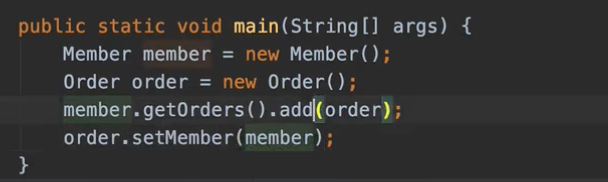
원래대로 하면 코드가 이런 식으로 뭔가 비즈니스 로직에서 이렇게 해야 되겠죠. 그런데 문제는 member에 order를 넣는 거나, order에 member를 넣는 거나 둘 중에 하나를 깜빡할 수 있잖아요.
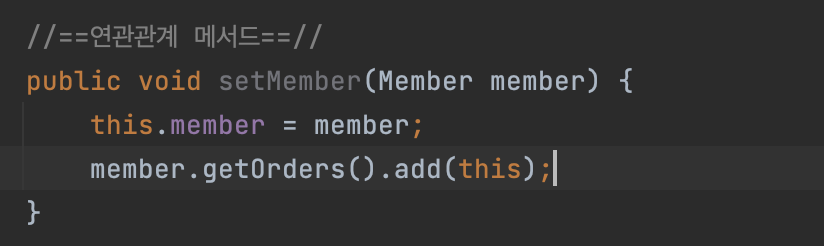
그래서 이 두 개를 원자적으로 딱 묶는 메서드를 만드는 거에요. 이렇게 하면,

코드가 하나로 줄겠죠. 이런 식으로 짜도 양방향 연관관계에 다 걸리는 겁니다. 자 이런 거를 연관관계 편의 메소드라고 하고요.
orderItem도 연관관계를 세팅할 때 orderItem랑 Order도 양방향 연관관계거든요.
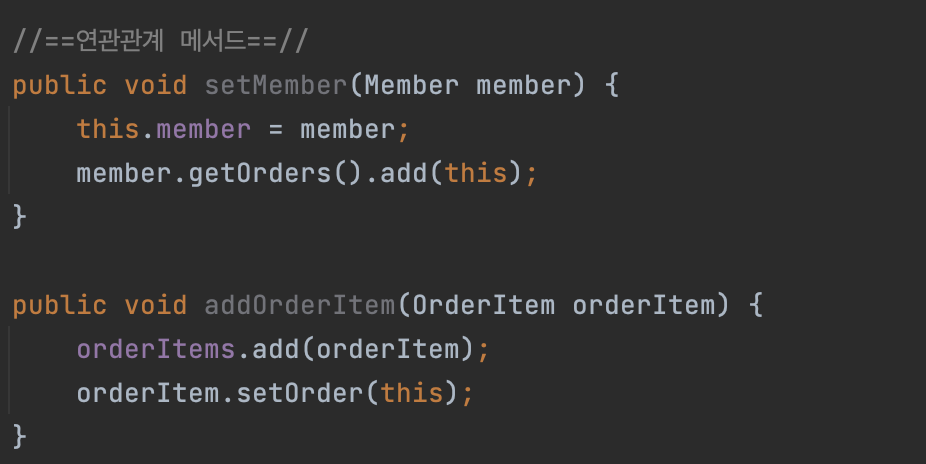
orderItems에다가 add 해가지고 orderItem 집어 넣고, 반대로 넘어온 orderItem에다가도 setOrder 해서 this를 넣어줍니다. 이 연관관계 편의 메서드의 위치는 양쪽이 있으면 어디가 좋냐면, 핵심적으로 컨트롤 하는 쪽이 들고 있는 게 좋습니다.
그 다음에 Delivery도 마찬가지로 Order와 양방향 연관관계거든요. 그래서 양방향에서는 Order랑 Delivery랑 연관관계 편의 메서드가 있으면 좋아요.
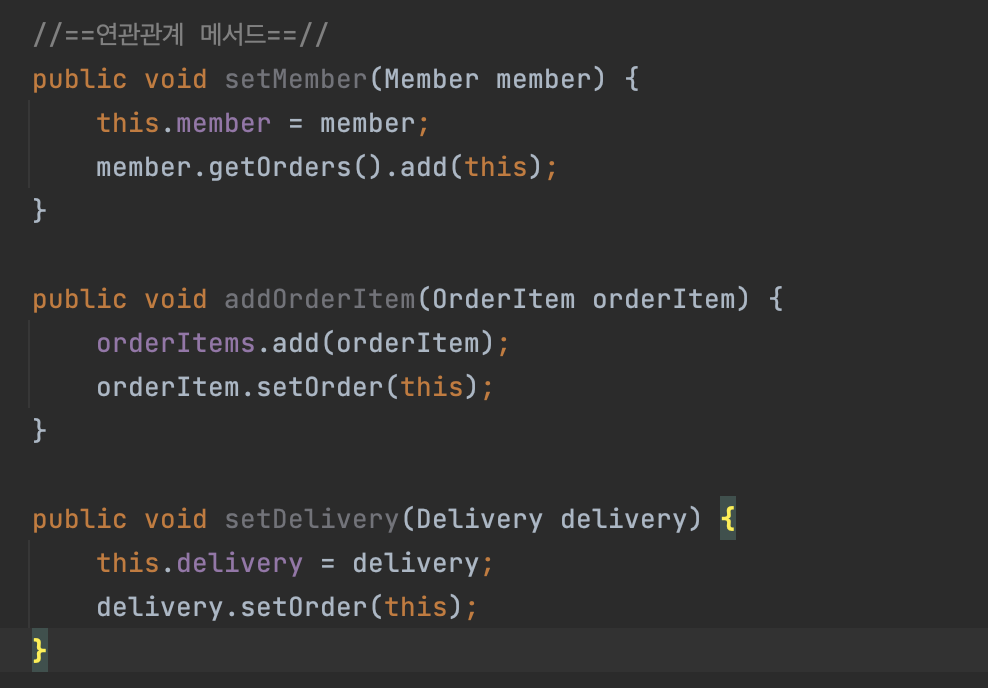
이렇게 집어 넣어주면 양방향이 딱딱 세팅이 됩니다.
이게 이제 연관관계 편의 메서드라고 부르는 애입니다. 양방향일 때 쓰시면 좋습니다. 양쪽 세팅을 하는 걸 원자적으로 한 코드로 딱 해결을 하는거죠.
그리고 또 하나 들어가야 될 게 양방향에서 남은 게 Category 쪽에 있었죠.

얘는 addChildCategory인데 Category가 셀프로 들어가죠. 얘도 양방향이죠. child를 집어넣으면 양쪽이 다 들어가야 돼요. 부모에도 들어가고 자식에도 들어가야 돼요. 부모 컬렉션에도 child가 들어가야 되고, 반대로 자식에서도 부모가 누군지를 바로 이렇게 this로 넣어주시면 됩니다.

이게 바로 연관관계 편의 메서드인데, 이걸 굳이 이렇게까지 관리해야 되나요? 이것에 대해서 기본편에서 제가 많이 설명을 드렸고, 이것 자체에도 내용이 길어서 여기서는 이정도까지만 설명을 드리겠습니다.
자 여러분 이렇게 해서 이제 대단원의 도메인 분석 설계가 완료가 되었습니다.
다음 시간에는 드디어 이걸 가지고 실제 개발을 해보는 거에요. 실제 서비스 클래스 생성, 리포지토리 서비스 클래스를 만들고 요구사항을 가지고 비즈니스 메서드 만들고 테스트 케이스 만들고 이렇게 해서 테스트가 정확하게 돌아가는지 만들어 보는 그런 실제 비즈니스를 구현하는 코드를 작성해 보겠습니다.
'스프링 > 실전! 스프링 부트와 JPA 활용1' 카테고리의 다른 글
| 애플리케이션 아키텍처 (0) | 2024.04.24 |
|---|---|
| 구현 요구사항 (0) | 2024.04.24 |
| 엔티티 클래스 개발2 (0) | 2024.04.19 |
| 엔티티 클래스 개발1 (0) | 2024.04.17 |
| 도메인 모델과 테이블 설계 (0) | 2024.04.15 |



